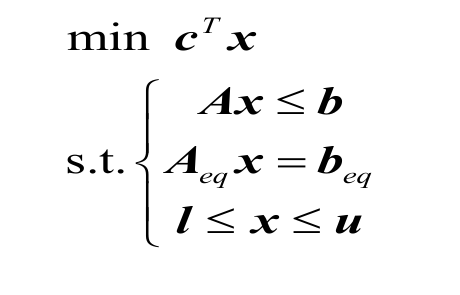一、BFS 模板
如下所示
set<Node> visited;
bool check(Node son);
int bfs(Node start)
{
// init
queue<Node> q;
q.push(start);
visited.insert(start);
while (!q.empty())
{
Node front = q.front();
q.pop();
for (son : q.neigbour)
{
// prune
if (check(son))
{
q.push(son);
visited.insert(son);
// son is the correct answer
if (ac(son))
{
return son.info();
}
}
}
}
return -1;
}
int main()
{
//...
int ans = bfs();
//...
return 0;
}其中有几部分需要一一强调,第一个是 check() 函数用于进行减枝,只有经过 check 的子节点会被加入队列。
bool check(Node son);