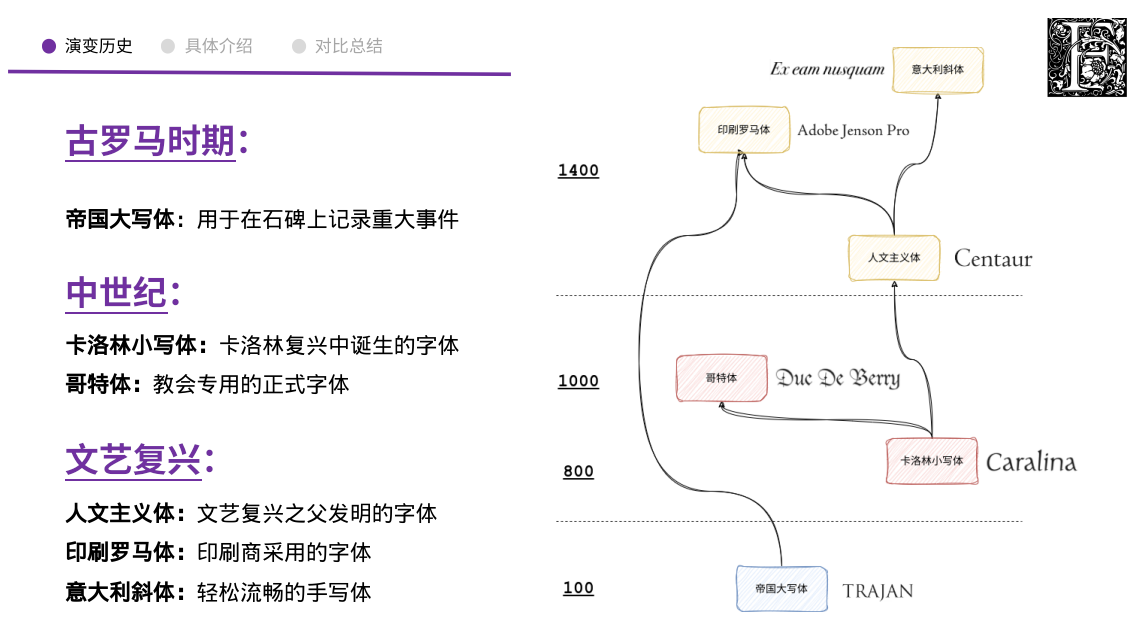
计算机组成 - 内存一致性
一、一致性
一致性(consistency)这个概念应该是来自于分布式理论的 CAP 理论
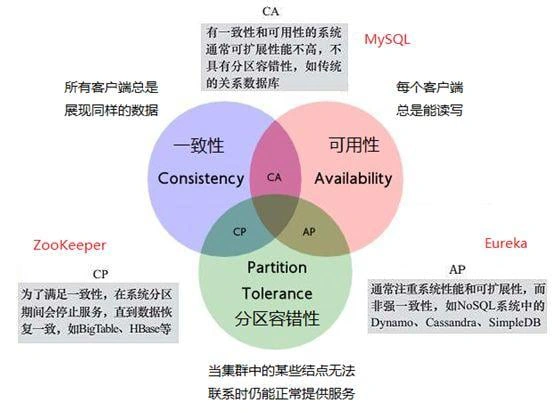
我觉得用人话来说就是对于多个观察者观察同一个事物,每个观察者观察到的现象是 “相同的”,那么我们就认为这个设计具有 “一致性”。“盲人摸象” 就是一个非一致性的例子,对于同一个事物,盲人们分别给出了 “柱子、山、石头” 等描述,就是不具有一致性的案例。
一致性和并行编程联系紧密,因为一致性保证了多个并行的实体,他们看到的共享资源是相同的。只有这样才能保证并行实体间的协作,如果实体看到的资源都是不一样的,比如说线程 A 给资源加了个锁,但是 B 没有看到这个锁,那么就会导致数据竞争的发生。盲人摸象的结局不正是因为盲人们对于大象的看法各执己见,最终大打出手吗?