随机变量的函数就是说通过函数映射的形式,将原来的一个或者多个随机变量放进函数里,然后得到一个新的随机变量。这里主要是分成了两种类型,一个是一元函数,另一个是多元函数(基本上都是二元函数)。这两种函数因为诞生的意义的不同,所以在研究方法和其他方面里都存在明显的差距。
对于一元函数,我觉得最漂亮的是关于标准分布的构造。这个思想是我见过构造性最强的数学应用,总之就是很漂亮的构造。
对于二元函数,会涉及到两个随机变量的相互作用,所以应用的数学工具会更加强大,比如说卷积,线积分,可以说是另一个层次的美感。
一、分布分类
正如摘要提到的,分布的描述对象不止限于客观对象。因此我们对现在研究的分布进行一个分类:
| 类别 |
分布 |
| 普通分布 |
正态分布,负指数分布,均匀分布等 |
| 标准分布 |
标准正态分布, χ2 分布,t 分布,F 分布 |
理解这补充的三种分布,最重要的是,本质上他们都普普通通的分布,与正态分布,负指数分布,均匀分布没有任何区别。我们对普通的分布,研究的是数字特征,研究他们的性质,对于标准分布,我们依然研究他们的参数,研究他们的性质。
当然,区别还是有的,他们与普通分布的最重要区别是,他们一般不是对客观世界某个试验的结果的描述,比如说负指数分布可以描述动物的寿命,服务系统的排队时间,正态分布可以描述人群的身高。但是这些标准分布并不能描述自然现象,也就是普通的随机变量,他们描述的是随机变量的函数,换句话说,他们描述的是对象是经过数学构造过的随机变量。所以他们的概率密度的数学形式更加复杂,而且莫名其妙,不容易让人理解。
那么我们为什么要这样自讨苦吃?好在了我们完全了解标准分布,我们知道他们的密度函数表达式是什么,虽然分布函数的表达式写不出来,但是我们有表,就等于知道了所有的概率分布。如果一个随机变量服从这些标准分布,我们就完全了解了这些随机变量,我们想求一个区间的概率密度,一查表,事情就解决了。
另外还有一个重要特点,就是标准分布呈现了连续构造的特征,我们构造 χ2 分布的时候利用了 ϕ ,构造 t 分布的时候利用了 χ2 和 ϕ ,构造 F 分布的时候利用了 χ2 。但是需要注意,虽然构造的时候,分布们互相调用,但是这种调用也没有办法看出任何有意义的联系。这种构造方式,一般是为了说明某个随机变量是随机变量,也就是说,发挥的是判定定理的作用。
二、标准分布
2.1 标准化随机变量
虽然这个不是标准分布,但是他的精神是一致的,就是不再描述客观世界中的随机变量,而是描述用函数构造出的随机变量。
对于随机变量 X 构造 X∗
X∗=DXX−EX
这个新的标准化随机变量,有以下数字特征:
EX∗=0
DX∗=1
2.2 标准正态分布
参数 μ=0,σ=1 的正态分布即 N(0,1) ,被称为标准正态分布,其概率密度函数和分布函数分别用 ϕ(x) 和 Φ(x) 表示。
之所以提出标准正态分布的概念,是因为为了方便实践,虽然正态分布函数没法用初等函数表示,但是我们可以通过查表来获得标准正态分布某个区间的概率。只要我们能在正态分布函数和标准正态分布函数中建立某种联系,我们就可以获得所有正态分布的区间概率。
在后面的介绍中,即使这些标准分布都可以给出概率密度的表达式,但是我都不记录,因为没必要,因为我们也不会对其积分,我们算概率用的是查表。
应用:
σ/nXˉ−μ∼N(0,1)
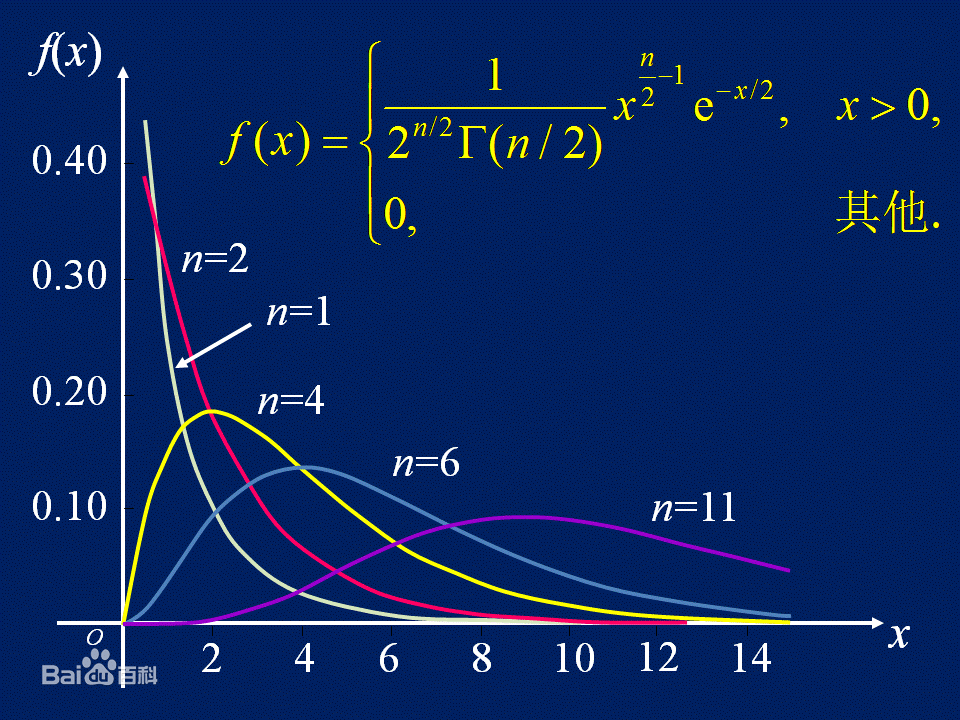
2.3 χ2 分布
判定:
若 X1,X2,X3,⋯,Xn,⋯ 相互独立,且都服从 N(0,1) ,则随机变量 ∑i=1nXi2 服从 χ2(n) 分布。
性质:
- 有一个参数 n,当 n 越大的时候,概率密度图像越平,最高点越向 x 轴正方向延伸
- 若 X∼χ2(n) ,有 EX=n,DX=2n
- 若 X1∼χ2(n1) , X2∼χ2(n2) ,则 X1+X2∼χ2(n1+n2)
应用:
(n−1)σ2S2∼χ2(n−1)
除了上面这个应用以外(也就是获得 σ 的置信区间),卡方分布还有一个重要应用是检验总体分布假设(这是我们高中就接触的),其原理是皮尔逊 χ2 统计量,这种统计量服从 χ2 分布。
K=npi∑i=1k(ni−npi)2∼χ2(k−1)
其中我们需要将数轴分为 k 个不相交的区间(如果是离散型,那么离散型随机变量有几个取值,就分几个就好了),这种说法应该是为了连续型随机变量,pi 是这些区间的理论概率,ni 是试验落在对应区间的个数。
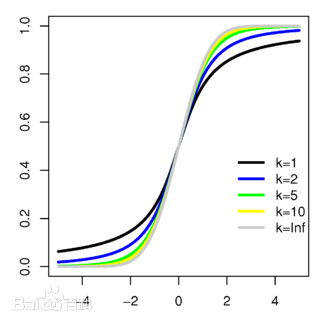
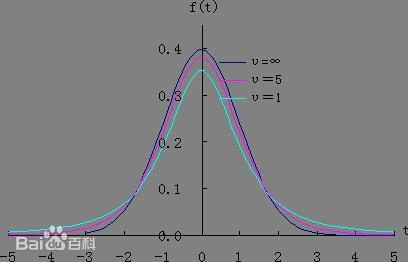
2.4 t 分布
判定:
若 X∼N(0,1),Y∼χ2(n) ,且 X,Y 相互独立,则 Y/nX 服从 t(n) 分布。
性质:
- t 分布关于 t=0 对称
- 当 n→+∞ 时, t 分布近似于 N(0,1) ,当 n 较小的时候, t 分布与正态分布有较大差异
应用:
S/nXˉ−μ∼t(n−1)
(m−1)S12+(n−1)S22(X1ˉ−X2ˉ)−(μ1−μ2)⋅m+nmn(m+n−2)∼t(m+n−2)
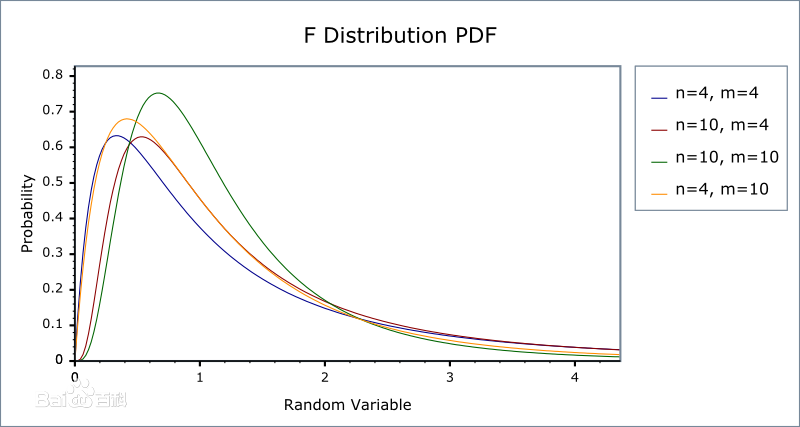
2.5 F 分布
判定:
若 X∼χ2(n1),Y∼χ2(n2) ,且 X,Y 相互独立,则 Y/n2X/n1 服从 F(n1,n2) 分布
性质:
应用:
S22/σ22S12/σ12∼F(n−1,m−1)
三、连续型随机变量的函数的分布
3.1 一维分布
这就是我觉得简单的那种,其关键点在于一个反函数,就直接拆开就好了,不会太难的。
3.2 二维分布
3.2.1 一般方法
已知二维连续型随机变量 (X,Y) 的概率密度为 f(x,y)。求 Z=g(X,Y) 的概率密度。
解:计 Dz={(x,y)∣g(x,y)≤z}。
FZ(z)=P{g(X,Y)≤z}=P{(X,Y)∈Dz}=∬Dzf(x,y)dxdy
fZ(z)=dzdFZ(z)
3.2.2 Z=X+Y
FZ(z)=P{X+Y≤z}=∫−∞+∞∫−∞z−xf(x,y)dxdy
做变量代换 y=t−x,然后有
∫−∞+∞∫−∞zf(x,t−x)dtdx=∫−∞z∫−∞+∞f(x,t−x)dxdt
所以有 Z 的概率密度为
fZ(z)=∫−∞+∞f(x,t−x)dx
当然,如果是更加普世一点的 Z=aX+bY+c,有
fZ(z)=∫ABˉf(x,y)dx
其中 ABˉ 是 z=ax+by+c 这条直线的有向线段。相当于是一种第二类曲线积分。
如果有 X,Y 是相互独立的条件,那么就会有更加优雅的结论,那就是
fZ(z)=∫−∞+∞f(x,t−x)dx=∫−∞+∞fX(x)⋅fY(z−x)dx
我们又管右端的积分叫做卷积(关于卷积,可以看我的其他博文有介绍)
fX∗fY(z)=∫−∞+∞fX(x)⋅fY(z−x)dx
如果独立的变量还是正态分布,那么我们还有更好的性质,即
如果我们有 Xi∼N(μi,σi2) 。且各个随机变量相互独立,那么有
Z=i∑kiXi+b∼N(i∑kiμi+b, i∑ki2σi2)
3.3 Z=max{X,Y}
已知二维连续型随机变量 (X,Y) 的概率密度为 f(x,y),分布函数是 F(x,y)。
FZ(z)=P{X≤z,Y≤z}=F(z,z)
fZ(z)=FZ′(z)
如果有 X,Y 是相互独立的条件,有
FZ(z)=FX(z)⋅FY(y)
3.4 Z=min{X,Y}
已知二维连续型随机变量 (X,Y) 的概率密度为 f(x,y),分布函数是 F(x,y)。
FZ(z)=P({X≤z}+{Y≤z})=P{X≤z}+P{Y≤z}−P{X≤z,Y≤z}=FX(z)+FY(z)−F(z,z)
同时也有:
FZ(z)=1−∬x>z,y>zf(x,y)dxdy
如果有 X,Y 是相互独立的条件,有
FZ(z)=1−(1−FX(z))⋅(1−FY(y))