一、总论
1.1 关于需求
我认为,在P7,我们设计的最终目的是实现一个看上去像单周期CPU的、具有反馈控制接口的流水线CPU。如果再将目标细化一些,那么就是两个小目标,那就是:
- 从外部(也就是软件程序开发者)看,流水线CPU被封装成了单周期CPU
- CPU可以为外部提供反馈信息,并且可以让外部根据反馈信息进而更改CPU的运行状态(整个过程叫做反馈,实现了这个功能的CPU具有了软硬件交互接口)
其中第一个需求,体现的是对硬件良好的封装能力,也就是极高的设计能力,设计者必须同时站在CPU内部和外部角度,从外部去检查没有流水线的任何细节漏出,从内部去实现这种伪装。对于第二个需求,体现的是对控制和接口更高层次的理解,我们的CPU的控制会变得更加复杂,会具有反馈和二次控制的功能,同时,软硬件接口交互也加大了理解的难度,因为有一部分功能交由软件负责,而我们不负责软件。
所以,在这一节,有两个重要的认知,第一个就是明确我们的需求是什么,第二个是,排除一些错误的观念,比如我一开始设计的时候,以为目标是像P6一样,最重要的是实现一个模块(比如说乘除模块),然后加上相关的指令就好了。但是在P7,实现了桥,计时器,协处理器只是很小很小,几乎完全不体现设计难度的部分,这是因为这些功能只是功能模块,与封装和接口的关系不太大。
如果再说的透彻一些,P7是对封装的理解与实践。
1.2 关于封装
首先先说一下,我们封装的目标就是把CPU弄得像设置了延迟槽的MARS一样。任何设计的需求的不清晰,都应该参照MARS的行为(而不应该根据宏观PC、犯罪指令或者其他二级理解概念进行理解分析)。
那么我们离这个目标差距在哪里呢?因为我们的CPU是流水线模式,所以在同一个时间节点会有多条指令并行处理,也就是说,我们在封装的时候的基本矛盾,就是多条指令并行的客观事实与单条指令顺序执行的封装假象之间的矛盾。
为了实现这个目标,我们需要实现以下具体需求:
- 为外界提供一个像正常的单周期PC行为(不会闲的没事跳变)的PC(在一个流水线里一般都有五个不同的PC),这个PC也就是我们说的宏观PC。
- 宏观PC这个概念不是内部设计构造出的概念,而是外部对内部设计的需求。对于宏观PC对应的指令,该指令之前的所有指令序列对 CPU 的更新已完成,该指令及其之后的指令序列对 CPU 的更新未完成
具体的实现下文介绍。
1.3 关于接口
我觉得接口最重要的概念是声明(不知道学术一点是不是叫协议),就是接口的双方需要具有相应的约束条件,比如说如果软件声明了不在异常处理程序中使用乘除模块hi和lo的值(可能只读不用),那么在硬件实现的时候,陷入中断的时候就可以不暂停乘除运算。所以这个的重中之重,就是理解教程中的软件到底承诺了什么,对于这种承诺的理解偏差,是导致很多人包括我,错误的原因。这也是P7除了封装以外最大的难度,因为封装只是设计能力,但是理解软件约束,考察的是理解能力。
1.4 关于信号
信号是控制实现的载体。在P4的时候,我将信号分成了三种(植物分类学爱好者的神奇癖好):使能、选择、功能。可以看到,这三种信号其实实现的一个目的,就是让CPU按照要求工作,比如说add来了,那么ALU就需要运行加法,寄存器就需要把结果存储进去。
但是随着设计需求的不断提高,我们发现有很多信号是没有办法进行这样的归类,在进入P5以后,比如说A值,T值,条件指令的condition,会发现这些信号是没有办法按照上面的分类进行归类的,这是因为他们是完全不一样的信号,他们不直接决定CPU的功能,而是间接地控制CPU,比如给出T值,T不会直接连到流水线寄存器的使能端,而是通过一个T值的比较,进而生成了stall信号。这些信号是二级信号。
然后我们在P7会发现,会有新的异常相关的信号,比如ExcCode,ExcReq,还有外部的reset信号(稍微特殊一点,容忍一下),或者IntReq信号,这些东西,也是没办法归类的。
我在新的信号分类体系中,我将其分为静态信号和动态信号,静态信号就是只用肉眼看汇编就可以分析出来的信号,比如说j就是跳转,目标就是那个地址,动态信号就是需要在运行的时候才能确定的信号,比如beq需不需要跳转?哪个数据需要转发?异常在哪条指令发生?中断啥时候来?这些都是不运行肯定确定不了的。
我为什么要在一个讲如何搭CPU的博客里讲信号。这是因为只有在有了这个明确的分类,我们才能意识到,我们在实现P7的时候,实现的信号几乎都是以动态信号的考察,实现动态信号比实现静态信号更为复杂,因为动态信号更加考验逻辑,静态信号啥时候像AT法那么难理解了。但是AT法还是有明确教程的提醒,大家不至于放松警惕,而P7教程的短小和实现的自由,很容易让人忽略这个点,比如说很多人(包括我)没有意识到各个清空信号的优先级问题(就是那个著名的缺少中断6/10)。如果在设计之初,就可以意识到这个事情,那么就不会粗心大意了。
1.5 关于中断
先明确一下本文的各个概念(只是约定,为了概念没有被混淆),不正常的情况分为两种:内部异常和外部中断,外部中断包括计时器中断和tb中断,所有不正常的情况都会导致CPU进入中断,也就是异常处理程序。我在整篇文章都会只用这几个概念:内部异常、外部中断、计时器中断、tb中断、中断。每个概念都不会有别的意思,也不会与其他概念混淆。
中断其实与过程(函数)调用极其相似,在《深入理解计算机系统》这本书中,说“中断就是不确定发生位置的过程调用。”我觉得是一个很好的类比。当发生中断的时候,就好像一个函数调用一样,会跳到一个固定的位置0x4180(仅是我们的CPU),然后开始一系列指令,最后用eret返回(就好像jr一样)。然后经过这个函数,我们就可以重新执行原来的程序了。
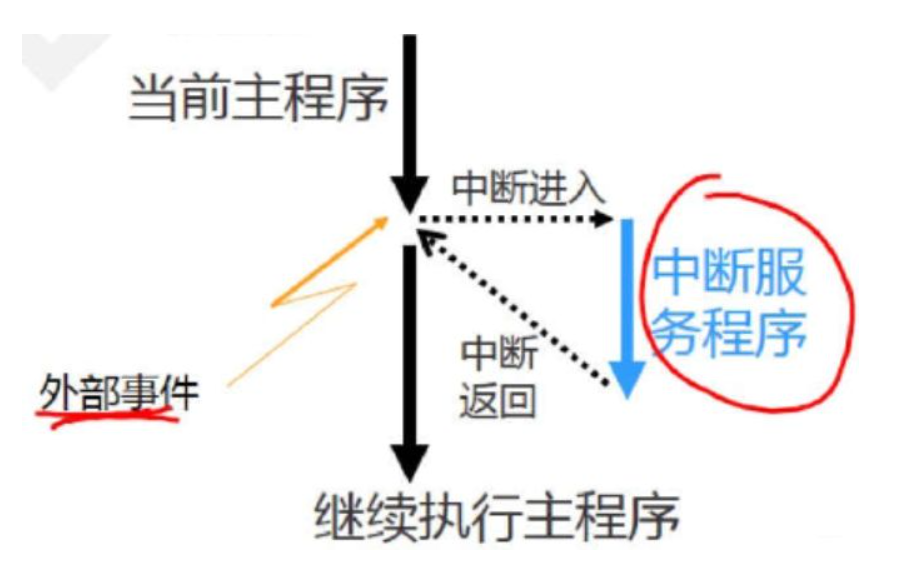
可以看到和函数调用具有很多的相似性。但是同时也应该意识到,正是因为发生中断的位置是无法确定的,所以要想将中断封装成单周期CPU,是有很大的难度的。
1.6 关于实现
首先要强调,P7是很花费时间的,我是从上周开始做准备,看各种资料,从上周五开始写代码,写了周五一天,周六一天,周日晚饭前写完了,然后开始做测试,debug,要是没有先是两位最彪悍的头脑帮我肉眼debug,然后另一个彪悍的头脑给出了彪悍的数据,我是不可能在周日晚上11点de完的,而这之后,为了保证CPU没啥大问题,我又进行了周一晚七点到十一点的对拍,然后现在在写我的设计文档。虽然我确实手慢脑子笨,但是也不得不说,P7挺花时间的。
吴佬给出了一个实现顺序是先CP0,然后桥,然后计时器。我当时就是按照这个顺序走的,但是效果不太好。原因是正如前文阐述,P7的难点不在模块的实现,而是在封装和接口的设计,就好像P5的难点不在于流水线寄存器该咋写,而是在转发和阻塞逻辑的设计。所以我觉得应该先设计中断相关,不需要设计任何模块,就可以完成这个设计,只需要假定自己已经有了一个信号Req,是中断信号,只要这个信号置1,就会中断就能完成大部分设计。
实现流程大约一下几步(没有深思熟虑,单纯给出任务量)
- 各个模块对内部异常的检测
- ExcCode的流水
- 各个模块的内部异常的容忍处理(比如变成nop之类的)
- 各个模块对中断的反应(比如流水寄存器需要清空,写的东西要清掉,或者不写)
- 实现CP0
- 实现桥
- 实现mips整体架构(感觉可以先实现这个,然后实现桥会更好)
- 实现三条指令,实现相关控制信号
- 提交,然后debug(当然可能AC)
- 了解tb功能和MARS的导出,使其可以读两个文件
- 对拍,在对拍过程中发现要么是CPU错了(只有这种是有用的),要么是CPU实现的不一致,要么是tb错了,要么是汇编写错了。感觉情侣档做这个一定很有效,这个比做过山车刺激多了,吊桥效应拉满了。对完拍的我看岳哥哥都眉清目秀的。
- 改bug
随着有大佬通过课上强测、自动化对拍机的开发和新的tb的产生,之后的实现速度应该会加快,这里跪求一波。
最后说一下对于资料的学习,首先声明,因为我学习的某些独特性,以下建议我不负责,请勿随意模仿。教程提供了很多资料,我感觉还是《SMRL》最香,然后要是能看到《深入理解计算机系统》,那么从Y-86一路看下来,最后看中断,还是挺好的。我没有看课件,《软硬件接口》我觉得写得不太清楚,《数字电路设计》也是同样的毛病。
二、新模块
2.1 CPU模块
这里不是简简单单的将P6的mips模块改成CPU就完事了,CPU的端口是需要设计的(可以发挥设计能力了),这里其实也体现了接口的一个特性,因为CPU成了内部模块,所以之前那些最外部模块的接口要求,CPU模块就不用理会了,比如又可以把端口的命名风格跟自己的命名风格统一了,而不用考虑tb接口的命名风格了。
比较值得注意的是,CPU相比于原来的mips模块,多了两个功能性端口(其他端口一般只是改个名),一个是HWInt,用来接收中断;一个是IntReq,用于测试约定。
| 端口 | 方向 | 解释 |
|---|---|---|
| clk | IN | 时钟信号,保留 |
| reset | IN | 复位信号,保留 |
| i_inst_addr | OUT | 取指地址,因为IM的取指是不通过桥的,所以保留原有设计就好了 |
| i_inst_rdata | IN | 取出来的指令,保留 |
| CPUIn | IN | ProcessorReadDate,这个与之前不一样了,是因为ProcessorReadDate的来源不在只有DM了,还有计时器,所以这个数据需要接受BRIDGE的输入 |
| HWInt | IN | 用于传递来自计时器和外部的中断信号 |
| VAdd | OUT | 这个也是,CPU只生成一个地址,具体根据地址选择不同的IO,是桥的功能,所以需要输入到BRIDGE中 |
| CPUOut | OUT | ProcessorWriteDate,这个需要输入到BRIDGE中 |
| CPUByteEn | OUT | 这个必须从这里输出,因为桥产生不了位选信息,需要输入到BRIDGE里处理是否为0,但是其他的写使能信号,直接从BRIDGE中生成 |
| IntReq | OUT | 为了测试约定,跨过地址限制去写7f20 |
| m_inst_addr | OUT | 评测用的,保留就好了 |
| w_grf_we | OUT | grf 写使能信号,评测用的,保留 |
| w_grf_addr | OUT | grf 待写入寄存器地址,评测用的,保留 |
| w_grf_wdata | OUT | grf 待写入数据,评测用的,保留 |
| w_inst_addr | OUT | W 级 PC,评测用的,保留 |
| macroscopic_pc | OUT | 宏观PC |
2.2 BE模块
桥的端口声明:
| 端口 | 方向 | 位数 | 解释 |
|---|---|---|---|
| VAdd | IN | 32 | 获得CPU需要的地址,根据这个地址判断需要选择哪个设备读写数据 |
| CPUByteEn | IN | 4 | 这个信号仅依靠BRIDGE无法自己产生,所以需要输入 |
| DMOut | IN | 32 | 需要输入DMOut(m_data_rdata),挑选要读出哪个数据 |
| TC0Out | IN | 32 | 需要输入TC0Out,挑选要读出哪个数据 |
| TC1Out | IN | 32 | 需要输入TC0Out,挑选要读出哪个数据 |
| DMAdd | OUT | 32 | 如果读写DM,那么这要从这里输出,否则置0,需要连接m_data_addr |
| TC0Add | OUT | 30 | 如果读写TC0,那么就要从这里输出,否则置0,只有30位的原因是只支持按字读写 |
| TC1Add | OUT | 30 | 如果读写TC0,那么就要从这里输出,否则置0 |
| DMByteEn | OUT | 4 | 如果是在写DM,那么这个值就与CPU产生的ByteEn一样,不然就置0,连接m_data_byteen |
| TC0WE | OUT | 1 | 如果是在写TC0(需要结合CPUByteEn判断),那么就置1,否则置0 |
| TC1WE | OUT | 1 | 如果是在写TC1(需要结合CPUByteEn判断),那么就置1,否则置0 |
| BEOut | OUT | 32 | 需要在DMOut,TC0Out,TC0Out中挑选一个,输出到CPUIn中 |
可以看出,桥功能的实现,最重要的就是根据VAdd判断到底选择了哪个IO设备,也就是说,里面会有三个线,来根据VAdd的范围来判断命中了哪个仪器。然后才能对输入输出的各种数据进行选择。
桥的功能,主要是根据VAdd范围,来判断写使能信号和读数据,但是写数据还是直接连接在了相应端口,所以确实不太美观。
其实m_data_addr,TC0Add,TC1Add都可以统一成VAdd,因为反正有写使能信号和读选择把关,这样处理的原因只是因为美观和规范(CPU只通过桥与存储部件沟通,而不是自己直接沟通,复杂的mips设计里应该会涉及对VAdd的操作,而不是直接截断这种简单处理),没有任何实际意义。
2.3 计时器模块
计时器还是一个挺常见的中断源的(这个在嵌入式开发中特别常见,我记得51单片机上应该是装了4个?),虽然不像键盘鼠标那么好理解,但是跟CPU是在同一个时钟域,所以外部中断处理起来还是很方便的。在书上应该也有介绍,大家可以有兴趣了解一下。
这个是给的源文件,所以难度就在于看懂它,主要是要注意是30位的地址,连端口的时候注意不要输入一个32位的地址就好了。然后但是为了理解,我就又自己写了一个TC,采用的是我在Pre那篇文章里提的状态机风格,应该很好读懂,列于下:
`timescale 1ns / 1ps
module myTC(
input clk,
input reset,
input en,
input [31:0] TCAdd,
input [31:0] TCIn,
output reg [31:0] TCOut,
output IRQ
);
parameter
INIT = 0, //初始态,对应的是代码中的IDLE
LOAD = 1, //加载态,加载Count中内容
CNT = 2, //计数态
ZERO = 3; //计数为0态,对应代码中INT,但是其实不准确,因为IRQ在IDLE中可能也置1
//这里没有采用声明数组的方式,用这个更清楚楚一些
reg [1:0] status, nextStatus;
reg [31:0] Ctrl, nextCtrl, Preset, nextPreset, Count, nextCount;
reg isZero, nextIsZero;
//Ctrl[3] IM被置位1的时候允许中断
//Ctrl[2:1] Mode模式位
//Ctrl[0] 寄存器使能位
reg IEn, CntEn;
reg [1:0] Mode;
always @(*) begin
IEn = Ctrl[3];
Mode = Ctrl[2:1];
CntEn = Ctrl[0];
end
//当允许中断,且isZero为0的时候,就可以发出中断请求
assign IRQ = IEn & isZero;
//做一个地址映射
always @(*) begin
case(TCAdd)
0 : TCOut = Ctrl;
1 : TCOut = Preset;
2 : TCOut = Count;
default : TCOut = Ctrl;
endcase
end
/*
这段代码出现在了官方代码中,其实是为了保证display的正确输出
如果store Ctrl寄存器只store低四位,前面的高位不能修改,只能是0
所以用load做中间变量达到这个效果,display才是正确的
*/
//wire [31:0] load = (TCAdd[3:2] == 0) ? {28'h0, TCIn[3:0]} : TCIn;
// about status
always @(*) begin
if(en)
nextStatus = status;
else begin
case(status)
INIT :
//如果使能,才进行加载
if(CntEn) nextStatus = LOAD;
//否则维持原态
else nextStatus = INIT;
LOAD :
nextStatus = CNT;
CNT :
if(CntEn) begin
if(Count > 1) nextStatus = status;
else nextStatus = ZERO; //计数器到0了
end
//这是要重新加载新数的前兆,即停止计数,所以状态要回到初态
else
nextStatus = INIT;
ZERO :
nextStatus = INIT;
default :
nextStatus = INIT;
endcase
end
end
// about Ctrl
always @(*) begin
if(en) begin
if(TCAdd[3:2] == 2'b00) //写Ctrl寄存器的时候,只写后四位
nextCtrl = {28'h0, TCIn[3:0]};
else
nextCtrl = Ctrl;
end
else begin
case(status)
INIT, LOAD, CNT :
nextCtrl = Ctrl;
ZERO : begin
nextCtrl = Ctrl;
if(Mode == 2'd0)// 在模式0下,CntEn只维持一个周期
CntEn = 0;
end
default :
nextCtrl = Ctrl;
endcase
end
end
//about Preset
always @(*) begin
if(en) begin
if(TCAdd[3:2] == 2'b01)
nextPreset = TCIn;
else
nextPreset = Preset;
end
else begin
case(status)
INIT, LOAD, CNT, ZERO :
nextPreset = Preset;
default :
nextPreset = Preset;
endcase
end
end
// about Count
always @(*) begin
if(en) begin
if(TCAdd[3:2] == 2'b10)
nextCount = TCIn;
else
nextCount = Count;
end
else begin
case(status)
INIT :
nextCount = Count;
LOAD :
nextCount = Preset;
CNT :
nextCount = Count - 1;
ZERO :
nextCount = Count;
default :
nextCount = Count;
endcase
end
end
//about isZero
always @(*) begin
if(en)
nextIsZero = isZero;
else begin
case(status)
INIT : begin
if(CntEn)
nextIsZero = 0;
else
nextIsZero = isZero;
end
LOAD :
nextIsZero = isZero;
CNT : begin
if(Count == 1)
nextIsZero = 1;
else
nextIsZero = isZero;
end
ZERO : begin
if(Mode == 2'd1) //模式1只产生一个周期的高位信号
nextIsZero = 0;
else //模式0会一直产生
nextIsZero = isZero;
end
endcase
end
end
always @(posedge clk) begin
if(reset) begin
status <= 0;
Ctrl <= 0;
Preset <= 0;
Count <= 0;
isZero <= 0;
end
else begin
status <= nextStatus;
Ctrl <= nextCtrl;
Preset <= nextPreset;
Count <= nextCount;
isZero <= nextIsZero;
end
end
endmodule 还有一个坑点是Count是只读的,所以如果storeCount寄存器,会异常,我也不知道为啥没有注意到。
状态图如下
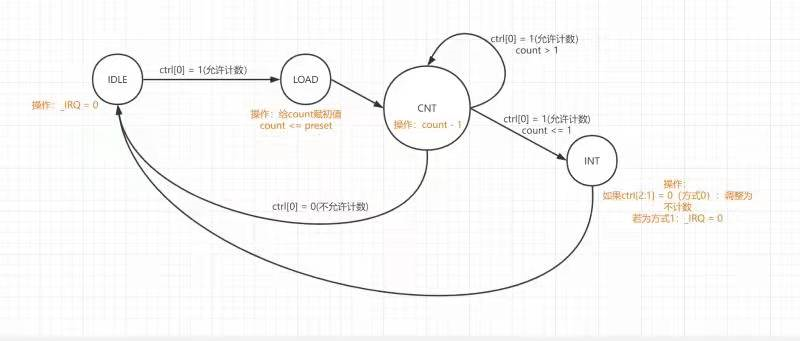
在模式0下:当计数器倒计数为 0 后,计数器停止计数,此时控制寄存器中的使能 Enable 自动变为 0。当使能 Enable 被设置为 1 后,初值寄存器值再次被加载至计数器, 计数器重新启动倒计数。 模式 0 通常用于产生定时中断。例如,为操作系统的时间片调度机制提供定 时。模式 0 下的中断信号将持续有效,直至控制寄存器中的中断屏蔽位被设置为 0。
在模式1下:当计数器倒计数为 0 后,初值寄存器值被自动加载至计数器,计数器继续倒 计数。 模式 1 通常用于产生周期性脉冲。例如,可以用模式 1 产生步进电机所需的 步进控制信号。不同于模式 0,模式 1 下计数器每次计数循环中只产生一周期的中断信号。
模式0计时结束后,一直保持中断,直到en或IM被修改,模式1计时结束后,中断一个周期,再重新计数。可以理解为中断保持的逻辑不同。
2.4 CP0模块
CP0是系统控制协处理器,CP1是浮点协处理器。
通用寄存器k0,k1(26,27号寄存器)是两个(由软件约定)预留下来的用于异常处理代码中的通用寄存器
CP0中不仅有教程中要求的四个寄存器,还有其他加起来总共大约是16个的寄存器(MIPS刚出现的时候,最多可以有32个CP0寄存器),所以课上要求的编号是十几就不奇怪了,在这里记录一下编号
| 寄存器 | 编号 |
|---|---|
| SR | 12 |
| Cause | 13 |
| EPC | 14 |
| PRId | 15 |
那么即使是四个寄存器,也有很多功能域,我们需要用哪些挑选哪些功能域去实现呢?
最简单的办法,就是教程的提交要求里面都给写好了,照着实现就好了。如果是从理论出发的话,那么功能域的实现其实是一个软硬件交互的问题,每实现一个功能域,软件(这里指的就是异常处理程序)对硬件的控制或者了解就多了一些,如果不实现BD,那么异常处理程序就无法研究延迟槽指令或者分支指令。
以上是一些小知识的补充,跟具体实现关系不大。
虽然我一直在弱化新模块的难度,但是其实新模块的功能实现还是挺难的(要是不与中断相比的话),具体到CP0,需要注意的有以下几点:
- 要利用输入的HWInt去做外部中断请求判断,而不是内部的IP,否则会慢一个周期
- 需要单独引出一个tbReq,用来响应tb中断,这是测试约定(后面会细说)
- 关于EPC存入的是哪一个值,需要利用BDIn信号进行判断
- Req来临的时候,是没有办法用mt来写东西的,所以当写寄存器的时候,有一个优先级判断(关于所有的写信号处理,后面有总结)
CP0的结构:
| 寄存器 | 功能域 | 位域 | 解释 |
|---|---|---|---|
| SR(State Register) | IM(InterruptMask) | 15:10 | 分别对应六个外部中断,相应位置 1 表示允许中断,置 0 表示禁止中断。这是一个被动的功能,只能通过mtc0这个指令修改,通过修改这个功能域,我们可以忽视一些中断 |
| EXL(ExceptionLevel) | 1 | 任何异常发生时置位,这会强制进入核心态并禁止中断 | |
| IE(InterruptEnable) | 0 | 全局中断使能,该位置 1 表示允许中断,置 0 表示禁止中断 | |
| Cause | BD(BranchDelay) | 31 | 当置1的时候,EPC指向分支指令,否则指向当前指令 |
| IP(InterruptPriority) | 15:10 | 为 6 位待决的中断位,分别对应 6 个外部中断,相应位置 1 表示有中断,置 0 表示无中断。这个会每个周期被修改一次,修改的内容来自计时器和外部中断(就是输入是HardwireIntReq)。 | |
| ExcCode | 6:2 | 异常编码,记录当前发生的是什么异常 | |
| EPC | - | - | EPC 寄存器负责保存中断/异常时的 PC 值 |
| PrId(Processer ID) | - | - | 通常存入处理器 ID,可以用于实现个性的编码 |
关于为啥IP这个名字这么奇怪,是因为因为咱们的CPU不支持不同中断的分类处理,同时也不支持不同中断同时发生时优先级比较,那么IP的功能相当于只被限制在了记录有没有中断,然后与InterruptMask配合,控制中断的使能,起不到优先级的作用。
CP0的端口声明
| 端口 | 方向 | 位数 | 解释 |
|---|---|---|---|
| clk | IN | 1 | 时钟信号 |
| reset | IN | 1 | 复位信号 |
| en | IN | 1 | 写使能信号 |
| CP0Add | IN | 5 | 寄存器地址 |
| CP0In | IN | 32 | CP0写入数据 |
| CP0Out | OUT | 32 | CP0读出数据 |
| VPC | IN | 32 | 受害PC |
| BDIn | IN | 1 | 是否是延迟槽指令 |
| ExcCodeIn | IN | 5 | 记录异常类型 |
| HWInt | IN | 6 | 输入中断信号 |
| EXLClr | IN | 1 | 用来复位exl |
| EPCOut | OUT | 32 | EPC的值 |
| Req | OUT | 1 | 进入处理程序请求 |
| tbReq | OUT | 1 | 有外部中断请求产生,主要是为了测试约定 |
CP0之所以这么多个端口,是因为除了正常的读和写功能之外,CP0还支持一些奇奇怪怪的读写功能,这些读写数据都需要另外开辟端口。
2.5 MDU乘除模块
因为P6我重构CPU来着,所以就没时间写博客了,在这里补一下乘除模块的实现。确实如果老老实实地等10个周期,然后算出结果,也可以立刻算出结果,然后用一个10周期的计数器产生busy信号,这样的话,两个状态机是解偶联的,更容易看懂和实现,而且根据P7的要求,也不要求中断的时候对MDU进行操作,所以这种“偷工减料”不会遭报应,还是挺好的一个设计思路。
计时逻辑如下
// about cnt
always @(*) begin
if(cnt > 0)
nextCnt = cnt - 1;
else
case(MDUOP)
MULT, MULTU : nextCnt = 5;
DIV, DIVU : nextCnt = 10;
default : nextCnt = 0;
endcase
end
always @(*) begin
if(nextCnt == 0)
nextBusy = 0;
else
nextBusy = 1;
end
always @(posedge clk) begin
if(reset) begin
cnt <= 0;
busy <= 0;
hi <= 0;
lo <= 0;
end
else begin
cnt <= nextCnt;
busy <= nextBusy;
hi <= nextHi;
lo <= nextLo;
end
end而且我用微薄的知识觉得,用计时器(就是所有的方法)其实不太像客观世界,如果乘除算的慢,应该是用中断提高吞吐量,而不是用计时器模拟一个延迟,所以可能大家都摆烂,五十步笑百步而已。
三、内部异常
3.1 内部异常的检测
这个部分教程提供的很全面了,此外,关于“犯罪指令 != 受害指令”,其实可以忽略这部分讲解的,因为等弄懂这个概念,会发现只要按部就班的布置异常的检测,这个部分一点问题都没有。反而是想要一上来区分这个概念的,有很大几率犯错误。
需要处理的事件是来自CPU的内部的,在P7中我们需要实现的异常检测有这样几种(除此之外,比较常见的还有系统调用,断点调试):
ExcCode的编码必须遵守规范,不然在交互的时候会出现问题
| 异常 | 编码 | 指令类型 | 情况 |
|---|---|---|---|
| Int | 0 | - | 中断 |
| AdEL(AddError_LoadInstr) | 4 | 所有 | PC地址未字对齐 |
| 所有 | PC地址超过 0x3000 ~ 0x6ffc | ||
| AdEl(AddError_LoadData) | lw | 取数地址未与 4 字节对齐 | |
| lh,lhu | 取数地址未与 2 字节对齐 | ||
| lh,lhu,lb,lbu | 不能取Timer中的值(应该是因为Timer只支持整字存取) | ||
| load | 计算地址时加法溢出 | ||
| load | 地址不在0x0000 - 0x2fffc 或 0x7f00 - 0x7f08 或 0x7f10 - 0x7f18 | ||
| AdES(AddError_StoreData) | 5 | sw | 存数地址未与 4 字节对齐 |
| sh | 存数地址未与 2 字节对齐 | ||
| sh,sb | 不能向Timer中存值(应该是因为Timer只支持整字存取) | ||
| store | 不能向Timer中的Counter写值 | ||
| store | 计算地址时加法溢出 | ||
| store | 地址不在0x0000 - 0x2ffff 或 0x7f00 - 0x7f08 或 0x7f10 - 0x7f18 | ||
| RI | 10 | 所有指令 | 出现未知指令(注意,已知指令中没有nop) |
| Ov(Overflow) | 12 | add,addi,sub | 算数溢出 |
这个的实现就由相应的功能部件完成就好了,非常简单,所以建议先从这里实践。
关于异常的检测,有的时候只依靠功能部件是实现不了的,所以有的时候还需要CU的辅助。比如我的ALU默认就是在进行加法运算,如果不考虑指令有没有用到ALU,很可能在一个没有加法操作的指令处产生内部异常。在下面的那个表格里会有介绍。
3.2 内部异常的容忍
在陷入中断处理内部异常之前,我们需要保证发生内部异常的指令能流到处理内部异常的流水级,所以我们需要对内部异常指令有一定的容忍度。教程里介绍了RI和取指地址未对齐,都是视为nop,这里全面的介绍一下:
| 流水级 | 检测部件 | 异常类型 | 异常条件 | 处理方式 |
|---|---|---|---|---|
| F | IFU | AdEL | 取指越界,未对齐 | 视为nop,也就是修改F_instr为0 |
| D | CU | RI | 指令未识别 | 视为nop,将默认识别从nop改为none,行为与nop相同 |
| E | ALU | Ov | 算数溢出 | 按照无符号方法进行,因为反正也写不进寄存器(Req清零),得先修改CU,让ALU意识到这是在进行有符号运算 |
| E | ALU | AdEL | 计算地址加法溢出 | 按照无符号方法进行,通过ExcCode流水到M级处理,得先修改CU,让ALU意识到这是在进行地址运算 |
| E | ALU | AdES | 计算地址加法溢出 | 按照无符号方法进行,通过ExcCode流水到M级处理,得先修改CU,让ALU意识到这是在进行地址运算 |
| M | DMI | AdEL | 地址未对齐、地址越界 | 通过CU使Byteen为0,这样就写不进去了,读的话不用处理,反正清零 |
| M | DMI | AdES | 地址未对齐、地址越界 | 不处理,清零即可 |
其实还可以一当产生内部异常,那么就视这条指令为nop,也挺好的,就是我没有采用。
3.3 异常码的流水
首先,必须将异常信号ExcCode流水,而不能直接处理,这是因为可能后面的指令发生异常的时间比前面指令发生异常的时间要早,比如说 j(D)- sw(E),如果这两个都是异常指令,那么j在D级就会产生异常,sw在M级产生异常(假设这个异常是超范围了),那么如果不流水,那么就是先处理 j 异常,显然不符合我们的要求,因为sw异常被忽略了(sw继续往后流,前面的流水级开始流异常处理程序,等异常返回之后,就会直接到跳转目标指令了,sw的异常没有得到处理)。所以我们将异常信号流水以后,就可以先处理sw异常,然后运行到 j ,再处理 j 异常。
流水异常码的本质是将CPU封装成一个单周期CPU,那些内部异常的指令实际上是发生了,但是我们要将其视为没有发生,因为他们比我们的宏观PC要大,我们从外部处理内部异常,考虑的只有宏观PC对应的那条指令。
这里有教程写会有一个内部异常优先级的问题,但是我觉得一条指令最多有一个异常,所以用优先级阐述好像不太合适,不过在实现方法上,还是很像具有优先级的形式的,也无怪乎有人视其为优先级问题了:
assign E_ExcCode = (Raw_E_ExcCode)? Raw_E_ExcCode :
(E_Ov)? `EXC_Ov :
(E_AdEL)? `EXC_AdEL :
(E_AdES)? `EXC_AdES :
0;这段代码的意思是,如果E级之前就有异常了,那么E级的异常码就是原来的异常码,如果没异常,那么如果E级发生了溢出,那么异常码就是Ov,如果发生了其他异常,那么就是对应的其他异常码。
四、外部中断
4.1 直观认识
中断与异常的区别是,中断不来自CPU的内部(或者说指令的执行过程),而是来自外部,比如说敲击键盘,鼠标,计时器)。我们有两种中断形式,一种是来自计时器的中断(因为有两个计时器,所以有两个中断信号:Timer0_IntReq,Timer1_IntReq),还要一个是tb提供的中断(interrupt),所以总共我们的CPU要可以接受三个中断,而在MIPS中CP0的设计,最多是六个,这也是IM和IP都是6位的原因。
按照教程要求,六位的IP输入内容,只有三位有效,我们这样接
assign HWInt = {3'd0, interrupt, TC1IRQ, TC0IRQ};具体到我们的CPU,我们理一下外部中断的结构,官方提供的tb会在宏观PC等于某一固定值的时候,给出一个中断信号,也就是interruption置1,然后这个信号输入到我们mips模块中,在mips模块中,有两个计时器,计时器也可以产生中断,那么就是三个中断信号,我们把它们联合成一个叫做HWInt(Hardwire Interruption)的六位的信号(之所以是6位,是约定),然后把这个HWInt信号输入到CPU模块中,然后这个信号再输入到CP0模块中,然后CP0模块根据掩码和中断使能,来判断要不要产生外部中断信号
wire IntReq = (|(HWInt & `IM)) & (~`EXL) & `IE;4.2 tb中断的响应
因为测试的约定,我们需要在响应了tb中断信号以后,给tb一个反馈信号,这样tb才能从1置0,具体的效果,可以看官方提供了在“tb_test”(这个名字有误导性)一个退化版的mips模块(好像只能响应中断信号)。interrupt维持了一个周期,从一个下降沿到另一个下降沿。
我们通过阅读教程提供的“tb_interrupt_demo.v”这个文件就可以发现,如果想把tb产生的interrupt置0,需要满足第2、3行的条件
always @(negedge clk) begin
if (~reset && interrupt && |m_data_byteen) begin
if (fixed_addr == 32'h7F20) begin
interrupt <= 0;
end
end
end因此,在mips模块中需要注意,这里m_data_addr除了DMAdd0x0000 - 0x2ffff这个范围,还有一个值是0x7f20,这个值是为了方便更好的与评测系统沟通产生的(是一种测试约定),当外部中断发生以后,需要写这个地址,无论写什么东西都可以,所以为了达到这种效果,需要在CPU上加上一个输出端口,来说明已经产生了外部中断请求,然后m_data_addr连接一个复用器,来实现这个功能。同时m_data_byteen也有这个问题,必须置1才能满足第2行的条件判断,所以也需要连接复用器
但是官方的反馈的实现,是将interrupt作为判断条件,来往7f20中写值,像这样
assign m_data_addr = (interrupt)? 32'h7f20 : DMAdd;
assign m_data_byteen = (interrupt)? 4'b1111 : DMByteEn;但是这样不太合理(据说不会在评测的时候出问题),因为有tb中断,不意味着一定会产生中断,因为还有其他SR的信号卡着呢,所以优雅的做法是在CP0里声明一个反馈信号,然后把这个反馈信号输出到mips这个层级
//CP0模块
assign tbReq = (HWInt[2] & SR[12] & (~`EXL) & `IE);
//mips模块
assign m_data_addr = (tbReq)? 32'h7f20 : DMAdd;
assign m_data_byteen = (tbReq)? 4'b1111 : DMByteEn;然后你就会发现,这个方法行不通,这是因为tbReq在下降沿产生,但是到了下一个上升沿,因为进入中断,所以EXL置1,所以tbReq就为0了,但是tb中的interrupt需要在下降沿检测这个信号,所以下降沿就发现tbReq为0,所以就没办法复位为0了,具体波形图如下
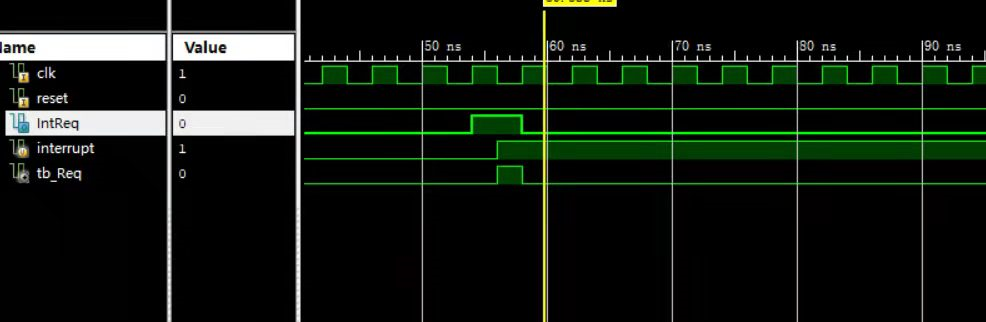
可以看到tbReq只维持了半个周期,所以为了延长tbReq的输出,我们做一个寄存器来延缓一个周期,具体写法如下
//为了处理测试约定
initial begin
tmpTbReq <= 0;
end
always @(posedge clk) begin
tmpTbReq <= tbReq;
end
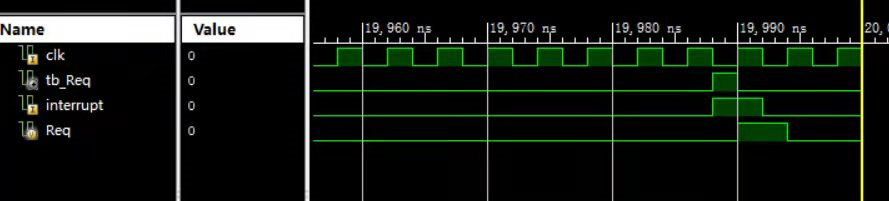
assign m_data_addr = (tmpTbReq)? 32'h7f20 : DMAdd;
assign m_data_byteen = (tmpTbReq)? 4'b1111 : DMByteEn;然后就可以看到合乎情理的波形图了(因为用的是杰哥的图,所以它的寄存器的名字叫Req,等价于代码里的tmpTbReq):
4.3 外部中断的类型
外部中断的特殊之处就在于它可以发生在任何一条指令上,所以比内部异常限制了指令的类别,外部中断更加自由。其难度或者说要点主要体现在:
- 对于任何一条被中断的指令,他的功能,无论是写寄存器,还是写主存,还是跳转,都不能发挥作用
- 中断的优先级是要高于异常的,所以如果同时发生,那么应该选择中断
- 在阻塞状态下发生中断,中断的优先级是要高于阻塞的
- 延迟槽指令被中断,需要注意延迟槽指令是有一个特殊标记的
- 延迟槽指令被阻塞产生了nop,然后nop被中断,此时nop也应该具有延迟槽标记,总的来说,延迟槽标记是与PC匹配的,而不是与具体的指令匹配的
五、陷入中断
5.1 避免写入数据影响和CP0的流水级
其实是很朴素的认识,当一个指令中断以后,我们就不执行后面的指令直到hanlder结束,但是实际上对于一个流水线CPU,同时会执行多个指令,我们必须把他们的影响都消除掉。指令的功能一般就三个:读,写,跳转。其中读没啥关系,不会对任何事情造成影响,跳转我们下一节再分析。那么主要分析一下写数据的影响,写的目标有E级的MDU的hi和lo寄存器,M级的DM、Timer、CP0寄存器,W级的GRF。如果我们将宏观PC设为M级PC我们都需要将其写使能关掉(用Req信号),除了W级的GRFEn。如果是设在了E级,那么只需要关掉MDU的写使能。(其实流水线寄存器也可以用这种方法分析,这为5.2清空流水线提供了另一个理论角度支持)
这里可以思考一个问题,就是CP0要放在哪一个流水级,如果按照上面的分析,如果不考虑另外构造一些结构,那么最好放在E级,因为E级的时候没有一条指令执行了写操作,这样我们才可以清空流水级,避免写入数据影响。如果放到M级实现,那么mthi和mtlo如果在M级被外部中断,那么他们的影响(写了E级的MDU),是没有办法挽回的。
但是在E级实现CP0比较困难,是因为指令在M级有可能会产生异常,所以这个异常信号可能是需要通过向前转发才能解决,因为我是在M级实现的(当时把hi和lo忘了),所以具体的E级的实现细节不太清楚。
但是评测机制考虑到了这种情况,它是允许M级CP0的设计的,也就是说,如果中断发生在M级的mtlo和mthi,那么是可以不撤回其在E级写入的数据的。这是比较让人欣慰的地方。
此外,造成影响的指令还有乘除法指令mult这一类,这一类是无论将CP0设计在哪一个流水级,都没有办法很简易的解决的。这个问题在客观世界的MIPS上也有,那么他们是怎样解决的呢?
最初的体系结构允许乘除法运算不停止,就是就算是发生中断也不停止。但是这样会造成问题,比如这个
mflo $8
mult $9, $10如果发生中断的是mflo指令,那么返回的时候还是重新执行mflo,但是此时mult已经将新值存入lo了,读出的值可能就是新值了,所以我们在软件编程的时候要避免这种情况(在这两个指令之间插最少2个非乘除指令)
我们好像实现的就是这种最初的体系结构,是依靠软件而非硬件避免这个漏洞的。
实际上,好像乘除是不需要处理的,因而一条或多条指令的执行效果可以被理解为对内存、各类寄存器等时序部件产生的影响。有些指令连续地重复执行多次后时序部件数据可能保持一致,如 mul、mthi 等;而有的则并不一定保持一致,如 add、sub 等。这就是了一部分理由,只要我们保证异常处理程序中没有mfhi和mflo,就不会产生任何问题(据说助教哥哥保证了)。
上面这种现象叫做等幂原理,这个原理在教程中被阐述成了执行效果,大概说的就是这个意思。
5.2 清空流水线
我们要实现支持异常与中断的CPU,有一个概念是绕不过的,就是宏观PC,其定义是这样的“该指令之前的所有指令序列对 CPU 的更新已完成,该指令及其之后的指令序列对 CPU 的更新未完成”。为了达到这种效果,就要求我们对流水线上的PC值有一个很好的控制,但是在实现CPU的过程中,需要很多插入nop操作(准确的说,是不让一些流水级的指令产生影响),比如说复位reset,阻塞时对E级的flush,进入handler时对D,E,W流水线的Req清空(如果实在M级进入handler),eret时对其后指令的清空。
在我原来的实现中,阻塞flush(当阻塞发生的时候,E级插入的nop)的实现其实就是把stall直接接入到了E级流水线寄存器的reset端口中,但是这种流水线寄存器是粗糙的,这是因为reset是把PC重新调整成0x3000(这是复位的要求),而这种清空显然是没法满足我们对于宏观PC的要求的,如果贸然的将flush理解为reset,那么宏观PC有一段时间就会变成0x3000,这显然是我们不希望看到的。不同的清空,对其中PC寄存器(不是F级那个)的要求也就不一样,大致有以下几种情况:
对于reset信号,其中的PC寄存器,当信号来临后,恢复到0x3000,不然刚开始一段时间,宏观PC(我的M_PC)会有一个不定值。
对于flush信号(其实就是stall信号),其中的PC寄存器,我们需要让其用下一条指令的值,也就是说,E级一旦flush,他的PC就会变成此时D级的PC。
对于Req信号(中断来了),同样需要清空D,E,M流水线,那么可不可以用我们刚刚实现的flush功能呢,不可以,这是因为宏观PC的定义是“该指令之前的所有指令序列对 CPU 的更新已完成,该指令及其之后的指令序列对 CPU 的更新未完成”,所以如果让中断后的D,E,M的PC保持,其他值清空,那么就像已经执行过这些指令一样,显然是不合理的,所以对于Req信号,我们对PC的要求是让其清零的时候变成0x4180,这样才合理。
此外,IFU也需要类似的修正(因为里面有PC寄存器)。
| 信号 | 流水寄存器中PC行为 |
|---|---|
| reset | 复位到0x3000 |
| flush | 用下一个值 |
| Req | 复位到0x4180 |
| eret | 不在这里实现,用去掉延迟槽的方法实现 |
5.3 EPC的写入
发生中断的一个重要行为就是将中断指令的PC写入EPC,有点像函数跳转之前,要将返回地址写入$ra。但是其实这么说不严谨,应当这样表述,对于异常情况,其实只用考虑是不是延迟槽指令,如果是延迟槽指令,那么存的是异常指令PC - 4,如果不是,那么就存PC。这样造成的结果就是,返回的时候会重新执行异常指令(如果异常处理程序不对EPC进行修改的话)对于中断情况,EPC存入的是中断来临的那个周期的M级的PC。具体的原因和用意教程里介绍了。
所以我们发现,判断一个指令是不是延迟槽指令,决定了我写入EPC的行为。那么应该怎样判断一条指令是不是延迟槽指令呢?我们说,必须在F级判断,然后流水,这是因为等到了M级在判断存在如下问题:当异常指令进入M级(准确的说,是CP0所在的流水级)的时候,直接看前一条指令是不是跳转指令,这个方法不行,因为跳转指令和延迟槽之间可能会插入nop(因为阻塞),比如
lw $t0, 0($0)
j A
add $t0, $t0, $t0
Aadd(E)- nop(M)- j(W),这时如果add溢出了,那么等add到M级的时候,会发现他前面是nop(W),此时就会被认为add不是延迟槽,就会错误。
所以我们需要在F级就进行判读,看D级的指令是不是跳转指令。另外,需要注意的是,按照教程要求,无论跳转指令跳不跳转,都需要将其后的那条指令视为延迟槽指令,所以判断标准不是NPCOP,而是是不是跳转指令。因此,BD是一个需要流水的信号。
至于为什么当一个异常指令是延迟槽指令的时候,就需要存入EPC - 4,也就是上一条的跳转指令,这是因为如果返回的是延迟槽指令,那么就顺序执行了,跳转指令就作废了。所以要回到跳转指令,那么为什么可以这样做呢?这是因为跳转指令具有等幂性。
5.4 清空优先级
正如5.2介绍的,有多个信号都会控制流水线寄存器,所有有可能同时会有多个信号会控制同一个寄存器,那么寄存器该展现怎样的行为呢?这是一个需要考虑的事情,比如说D级处于被阻塞状态,此时Req来了,那么他就应该立刻被清空,而不是保持原值,正在Req的时候,reset来了,那么CPU应该立刻复位,而不是进行异常处理,据说这个处理不当就会造成评测机中的缺少中断情况。故下列表展示优先级:
| 信号 | 优先级 |
|---|---|
| reset | 最高,因为复位大于一切 |
| Req | 次高,因为中断请求比内部阻塞重要 |
| flush/stall | 最低,因为是流水线信号,外部人员看不到 |
然后我们考虑,哪些寄存器中的项需要优先级,只有两个,一个是PC,原因之前论述过了,一个是BD,他在flush的时候需要保持原来的信息,因为在外部去看的话,会发现宏观PC是相同的,但是延迟槽标记是不同的,这显然是不正确的,如果针对被延迟槽的延迟槽指令下中断,那么下到了nop上,EPC就会被置位错误,造成评测的错误。
5.5 流水线寄存器支持
流水线寄存器主要需要改三个方面,一个是对不同清零信号的处理,一个是不同清零信号的优先级问题,一个是增加相应的数据项。
对于第1,2个问题,其实可以放在一起实现,这里提供两种方法:
always @(*) begin
if(reset) nextPC = 32'h3000;
else if(Req) nextPC = 32'h4180;
else if(flush) nextPC = PCIn;
else if(en) nextPC = PCIn;
else nextPC = PCOut;
end
if (reset | Req | flush) begin
instrOut <= 0;
EXTOutOut <= 0;
rsOutOut <= 0;
rtOutOut <= 0;
flag1Out <= 0;
BDOut <= (Req)? 0 : ((flush)? BDIn : 0);
ExcCodeOut <= 0;
end 对于第三条需求,我们这样考虑:肯定要加入BD和ExcCode,因为CP0是支持读功能的,所以从CP0Out也应该进入流水线。
此外,为了应对条件指令,对于分布式译码,我在流水线寄存器中加入了flag来表示条件判断(其实叫condtion更好),其实不属于P7内容,但是一并记录在此(原来是CMPOut来实现部分这个功能,但是不太严谨)。
| 数据项 | DREG | EREG | MREG | WREG |
|---|---|---|---|---|
| instr | 1 | 1 | 1 | 1 |
| flag1 | - | 1 | 1 | 1 |
| flag2 | - | - | 1 | 1 |
| flag3 | - | - | - | 1 |
| PC | 1 | 1 | 1 | 1 |
| EXTOut | - | 1 | 1 | 1 |
| rsOut | - | 1 | 1 | 1 |
| rtOut | - | 1 | 1 | 1 |
| ALUOut | - | - | 1 | 1 |
| MDUOUt | - | - | 1 | 1 |
| DMOut | - | - | - | 1 |
| CP0Out | - | - | - | 1 |
| BD | 1 | 1 | 1 | - |
| ExcCode | 1 | 1 | 1 | - |
| OvDM | - | - | 1 | - |
这里插句闲话,我觉得命题趋势是把risc往cisc那个方向去命题,在x86里有条件码(Comand Code),看上去就跟条件指令很类似。条件指令本质上都可以拆成简单的指令执行,但是非要在一个指令中实现,就很cisc。
六、指令功能
6.1 转发阻塞
关于转发,其实在写P6的时候,赵子齐哥哥就跟我探讨过关于hi和lo转发的问题,但是我当时太笨了,虽然他兴致盎然的说了一大堆,但是我一句都没有听懂(面带微笑,轻轻点头)。现在想想挺有道理的,mt类指令都是写指令,肯定是可以作为转发源的,而且因为Tnew是0,所以是很好的转发源,唯一需要考虑的是,AT法就需要扩容了,地址判断需要更加精密的操作,才能判断是否可以转发,所以无论是P6还是P7,我都没有实现转发。
其实还有一个折中的办法,是进行内部转发(小哥哥yyds),这个实现起来比较容易,效果比较好,但是我依然没有实现。
所以我们面对这三条指令,只能用阻塞避免冒险,然后我们考虑阻塞,mfc0,eret是读指令,所以不会阻塞别人,只有mtc0是写指令,会阻塞其他指令,那么对于mfc0,不需要阻塞,也不会有冒险,所以只有mtc0后接eret这种情况会阻塞,那么单独写一个阻塞就好了,还挺容易的,写法如下:
wire eretStall = (D_order == `eret) &&
((E_order == `mtc0 && E_rd == 5'd14) || (M_order == `mtc0 && M_rd == 5'd14));
需要强调的是,这里的转发阻塞仅限于这三条指令(是新加的内容),比如说mfc0是可以给其他指令转发的,用原有的阻塞转发系统。
mtc0是将rtOut中的内容写到以rd为编号的CP0寄存器中,所以这是一个又读又写的指令,但是需要注意的是,它的读,是可以利用转发和阻塞的,但是他的写目标,不在是通用寄存器,而是CP0,所以与其产生阻塞转发的,会是其后的mfc0(读CP0)和eret(读CP0中的EPC),所以其实是可以考虑搭建一个新的转发阻塞体系(这个问题在乘除的时候也有),但是在这里我们只实现阻塞功能,而不实现转发功能。
6.2 消除延迟槽
对于eret指令,我们有两种实现方法,一种是eret到了M级在进行跳转,那么其后就会跟着eret后面的指令(在D,E级),那么就需要把他们都清空了,此时的PC应该是EPC(后者eret的PC,也就是M_PC),但是无论是哪一个,都不是一个定值,都是需要加在流水线寄存器的PC输入端加MUX的,所以我没有采用。还有一种办法就是在D级就实现跳转功能,而且去掉延迟槽(注意,不是清空延迟槽),因为延迟槽之所以产生,是因为当跳转指令在F级的时候,NPC根据这条指令计算出了下一条指令,所以当跳转指令进入D级的时候,F级的PC就更新成了跳转指令的下一条指令,所以这个指令就会执行,哪怕跳转指令更新了PC,那也是在一个周期以后了(如果是在M级跳转,那么就是三条延迟槽指令,其实描述的就是上面eret的行为),所以要想去掉延迟槽,必须在i_inst_addr进行选择,当D级为eret时,就选择输出EPC的值,而不是PC寄存器中的值,就可以达到清空延迟槽的目的。其实还有一种思路,就是跳转是在F级实现的,但是如果在F级实现跳转,因为eret是一个读指令,所以他也是有阻塞需求的,但是我们的阻塞功能不支持F级的读指令,所以看上去不太好实现。
七、测试对拍
7.1 测试内部异常
这个部分是可以和MARS对拍的,也可以用自动测评机(虽然我什么也没有)。只是需要加一些处理。
我们知道MARS窗口界面是没有办法导出4180以后的内容的,所以只能用命令行把我们写的handler导出,命令如下
java -jar E:\Mars4_5.jar a db mc CompactDataAtZero dump 0x00004180-0x00004ffc HexText E:\code_handler.txt E:\source.asm但是一次一次弄太麻烦了,而且我个人觉得handler里内容都差不多(可能吧),里面也没有啥测试的要点,所以写一个通用的handler导出以后吃一辈子是一个可行的思路,这是我写的handler:
.ktext 0x4180
mfc0 $k0, $12 #取出SR的值到k0,看看对不对
mfc0 $k0, $13 #取出Cause的值到k0,看看对不对
mfc0 $k0, $14 #取出EPC的值到k0,看看对不对
mfc0 $k0, $13
ori $k1, $0, 0x007c
and $k0, $k1, $k0 #这里取出了ExcCode
beq $0, $k0, ERET #如果是中断,那么就退出handler了,处理中断的方式就是接着执行这条指令
addi $k0, $k0, 0xffff #稍带手测一下beq的延迟槽
mfc0 $k0, $14 #取出EPC的值到k0
lui $1, 0xffff
ori $1, $1, 0xfffc
and $k1, $k1, $1 #给EPC对齐了
addu $k0, $k0, 4 #给EPC+4
mtc0 $k0, $14 #重新赋给EPC
j ERET #异常处理完成,处理异常的方式就是跳过这条指令
nop
ERET:
eret导出以后是这个
401a6000
401a6800
401a7000
401a6800
341b007c
037ad024
101a000d
3c010000
3421ffff
0341d020
401a7000
3c01ffff
3421fffc
0361d824
3c010000
34210004
0341d021
409a7000
08001074
00000000
42000018用的时候就直接把16进制码存进handler.txt文件,然后放在工程目录下,就好了。
但是因为我们CPU的功能的强大,所以我们对于编写主程序也有了一定的要求,这是我写的一个模板
.text
addi $t0, $t0, 0xfc01
mtc0 $t0, $12 #给SR赋初值,IM全置1允许中断,属于初始化部分
#异常的产生构造主体begin
lui $t0, 0x8000
lui $t1, 0x8000
add $t2, $t0, $t1
ori $t3, $t3, 1 #一个检测位,说明回到了异常下一条指令,也可以不要,那么就是异常一条接着一条
#异常的产生构造主体end
end:
beq $0, $0, end #这个必须要有,因为CPU会把xxxxxx识别成RI,然后就在异常里出不去了
nop
.ktext 0x4180
mfc0 $k0, $12 #取出SR的值到k0,看看对不对
mfc0 $k0, $13 #取出Cause的值到k0,看看对不对
mfc0 $k0, $14 #取出EPC的值到k0,看看对不对
mfc0 $k0, $13
ori $k1, $0, 0x007c
and $k0, $k1, $k0 #这里取出了ExcCode
beq $0, $k0, ERET #如果是中断,那么就退出handler了,处理中断的方式就是接着执行这条指令
addi $k0, $k0, 0xffff #稍带手测一下beq的延迟槽
mfc0 $k0, $14 #取出EPC的值到k0
lui $1, 0xffff
ori $1, $1, 0xfffc
and $k1, $k1, $1 #给EPC对齐了
addu $k0, $k0, 4 #给EPC+4
mtc0 $k0, $14 #重新赋给EPC
j ERET #异常处理完成,处理异常的方式就是跳过这条指令
nop
ERET:
eret每次使用的时候,只需要替换中间的部分即可。相应的,因为需要往IM中读入两个部分的值,所以需要在tb中加一句话读取handler.txt,就在读code那句话下面就可以了
$readmemh("handler.txt", inst, 32'h460); //460 = (4180 - 3000) >> 2;7.2 测试外部中断
这个就没法白嫖往届学长的样例了,但是其实还是可以的,学长的样例只是缺少外置存储这一个设置,所以只要读懂tb,就可以把学长的tb修改一下,就可以跑了。(只能说小哥哥yyds)
但是无论怎样,测试外部中断的思路应该都是在tb上做文章,每一个code对应一个特殊的tb,自动化生成强的测试数据,应该不太可能了(但是感觉ch哥哥还是实现了,就是不知道是不是强的)。
7.3 对拍
不知道多久才能有大佬搞出自动化来,反正我是P7第一次跟人对拍,太折磨了,P7的测试数据又是人写的,所以有的时候不是CPU的问题,有的时候是tb的问题,有的时候又是汇编的问题,所以真的挺折磨人的,建议抱大腿。
不过话又说回来,P7的评测机行为是真的没办法提供有效信息,所以除了肉眼debug之外,就只有对拍一条debug的途径了,所以只能说都是生死有命,富贵在天的事情。
7.4 课上测试
这一届是三个强测,第一个是测试无中断无异常,第二是测试异常,第三个是测试中断,然后还有一个加指令。通过测试的条件是必须通过第一个测试,然后后三个完成两个即可通过。
P7的加指令是tltiu,这是一条在MIPS指令集中出现的指令,所以具体的描述可以看MIPS指令集,然后实现这个挺简单的,如果在CPU模块内直接写行为语句的话,大概十分钟就能写完(大佬应该会更快)。
八、软件约束
8.1 异常处理程序的行为
这个部分是一个科普,我们看异常处理程序一般都包括这么几个部分
.ktext 0x4180
_entry:
mfc0 $k0, $14 #取出 EPC 的值到 k0,没用
mfc0 $k1, $13 #取出 Cause 值到k1
ori $k0, $0, 0x1000 #给 k0 的第 12 位赋 1,其实就是在栈上找个地方存放寄存器上下文
sw $sp, -4($k0)
addiu $k0, $k0, -256
move $sp, $k0
j _save_context
nop
_main_handler:
mfc0 $k0, $13
ori $k1, $0, 0x007c
and $k0, $k1, $k0 #这里取出了 ExcCode
beq $0, $k0, _restore_context #如果是中断,那么就restore,目的是把寄存器上下文恢复了
nop
mfc0 $k0, $14 #取出 EPC 的值到k0
addu $k0, $k0, 4 #给 EPC + 4
mtc0 $k0, $14 #重新赋给 EPC
j _restore_context #恢复上下文,总的来说,处理异常的方法就是跳过这条指令
nop
_restore:
eret
_save_context:
sw $1, 4($sp)
sw $2, 8($sp)
sw $3, 12($sp)
sw $4, 16($sp)
sw $5, 20($sp)
sw $6, 24($sp)
sw $7, 28($sp)
sw $8, 32($sp)
sw $9, 36($sp)
sw $10, 40($sp)
sw $11, 44($sp)
sw $12, 48($sp)
sw $13, 52($sp)
sw $14, 56($sp)
sw $15, 60($sp)
sw $16, 64($sp)
sw $17, 68($sp)
sw $18, 72($sp)
sw $19, 76($sp)
sw $20, 80($sp)
sw $21, 84($sp)
sw $22, 88($sp)
sw $23, 92($sp)
sw $24, 96($sp)
sw $25, 100($sp)
sw $26, 104($sp)
sw $27, 108($sp)
sw $28, 112($sp)
sw $29, 116($sp)
sw $30, 120($sp)
sw $31, 124($sp)
mfhi $k0 #取出 hi 的值
sw $k0, 128($sp) #把 hi 的值也保留了
mflo $k0 #取出 lo 的值
sw $k0, 132($sp) #把 lo 的值也保留了
j _main_handler
nop
_restore_context:
lw $1, 4($sp)
lw $2, 8($sp)
lw $3, 12($sp)
lw $4, 16($sp)
lw $5, 20($sp)
lw $6, 24($sp)
lw $7, 28($sp)
lw $8, 32($sp)
lw $9, 36($sp)
lw $10, 40($sp)
lw $11, 44($sp)
lw $12, 48($sp)
lw $13, 52($sp)
lw $14, 56($sp)
lw $15, 60($sp)
lw $16, 64($sp)
lw $17, 68($sp)
lw $18, 72($sp)
lw $19, 76($sp)
lw $20, 80($sp)
lw $21, 84($sp)
lw $22, 88($sp)
lw $23, 92($sp)
lw $24, 96($sp)
lw $25, 100($sp)
lw $26, 104($sp)
lw $27, 108($sp)
lw $28, 112($sp)
lw $29, 116($sp)
lw $30, 120($sp)
lw $31, 124($sp)
lw $k0, 128($sp)
mthi $k0 #复原hi的值
lw $k0, 132($sp)
mtlo $k0 #复原lo的值
j _restore
nop
#程序首先从这里运行
.text
ori $2, $0, 0x1001
mtc0 $2, $12 #让CP0全局中断置1,而且允许外部中断(不包括TC0,TC1)
ori $28, $0, 0x0000
ori $29, $0, 0x0000
lui $8, 0x7fff
lui $9, 0x7fff
add $10, $8, $9 #造成溢出
or $10, $8, $9
end:
beq $0, $0, end
nop
还挺容易读懂的,但是需要强调的是,这不是测试样例的规范,也就是说,测试样例中的handler不长这个样子。
8.2 其他约束
首先声明,整个8.2节的全部内容,我一点都不负责,因为8.2节的内容造成的后果,请自行承担!!!
- 内部异常不需要考虑IE
- 乘除指令可以在中断发生时不被撤回
- 若中断发生在mthi或者mtlo,可以不撤回其操作
- 若中断发生在mthi或者mtlo的上一条指令,那么必须撤回mthi或者mtlo
- EPC在任何地方,任何情景都不需要考虑对齐
九、代码风格
9.1 指令分类
这是P6的内容,在这里介绍:
- load : lw, lh, lhu, lb, lbu
- store : sw, sh, sb
- cal_r : add, addu, sub, subu, sllv, srlv, srav, slt, sltu, sll, srl, sra, and, or, xor, nor
- cal_ia : addi, addiu, slti, sltiu
- cal_il : andi, ori, xori
- lui : lui
- branch2 : beq, bne
- branch1 : blez, bgtz, bltz, bgez
- jump_i : j, jal
- jump_r : jr, jalr
- link : jal, jalr(这里需要注意的是,这个分类并不是一个很好的分类,jalr的目的寄存器不是31,所以两者的共性不是很多)
- md : mult, multu, div, divu
- mf : mfhi, mflo
- mt : mthi, mtlo
指令与CU信号的关系
| 信号 | load | store | cal_r | cal_ia | cal_il | lui | branch1/branch2 | jump_i | jump_r | link | md | mf | mt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CMPOP | - | - | - | - | - | - | option | - | - | - | - | - | - |
| EXTOP | SE16 | SE16 | - | SE16 | ZE16 | LUI | SE16 | ZE26 | - | - | - | - | - |
| NPCOP | NORMAL | NORMAL | NORMAL | NORMAL | NORMAL | NORMAL | NORMAL/BRANCH | J | JR | - | NORMAL | NORMAL | NORMAL |
| PCSel | F | F | F | F | F | F | F/D | D | - | - | F | F | F |
| JumpSel | - | - | - | - | - | - | EXTOut | EXTOut | rsOut | - | - | - | - |
| ALUOP | ADD | ADD | option | option | option | - | - | - | - | - | - | - | - |
| SrcBSel | EXTOut | EXTOut | rtOut | EXTOut | EXTOut | - | - | - | - | - | - | - | - |
| MDUOP | - | - | - | - | - | - | - | - | - | - | option | option | option |
| STOREOP | - | option | - | - | - | - | - | - | - | - | - | - | - |
| ByteEn | - | option | - | - | - | - | - | - | - | - | - | - | - |
| LOADOP | option | - | - | - | - | - | - | - | - | - | - | - | - |
| GFREn | 1 | 0 | 1 | 1 | 1 | 1 | 0 | - | - | 1 | 0 | 1 | 0 |
| GRFInSel | DMOut | - | ALUOut | ALUOut | ALUOut | EXTOut | - | - | - | PC8 | - | MDUOut | - |
| GRFAdd3Sel | rt | - | rd | rt | rt | rt | - | - | - | 31/rd | - | rd | - |
指令与T值
| 分类 | rsTuse | rtTuse | E_Tnew | M_Tnew | FWSrc |
|---|---|---|---|---|---|
| load | 1 | - | 2 | 1 | DMOut |
| cal_r | 1 | 1 | 1 | 0 | ALUOut |
| cal_ia | 1 | - | 1 | 0 | ALUOut |
| cal_il | 1 | - | 1 | 0 | ALUOut |
| lui | - | - | 0 | 0 | EXTOut |
| link | - | - | 0 | 0 | PC |
| mf | - | - | 1 | 0 | DMUOut |
| store | 1 | 2 | - | - | - |
| branch2 | 0 | 0 | - | - | - |
| branch1 | 0 | - | - | - | - |
| jump_i | - | - | - | - | - |
| jump_r | 0 | - | - | - | - |
| md | 1 | 1 | - | - | - |
| mt | 1 | - | - | - | - |
指令与A值
| 分类 | A1 | A2 | A3 |
|---|---|---|---|
| load | rs | - | rt |
| cal_r | rs | rt | rd |
| cal_ia | rs | - | rt |
| cal_il | rs | - | rt |
| lui | - | - | rt |
| link | - | - | 31 |
| store | rs | rt | - |
| branch2 | rs | rt | - |
| branch1 | rs | - | - |
| jump_i | - | - | - |
| jump_r | rs | - | - |
| md | rs | rt | - |
| mf | - | - | rd |
| mt | rs | - | - |
因为是采用的是指令驱动型,所以我采用了宏定义的方式结合case语句来对指令进行分类,具体写法如下:
`define load `lw, `lh, `lhu, `lb, `lbu
`define store `sw, `sh, `sb
`define cal_r `add, `addu, `sub, `subu, `sllv, `srlv, `srav, `slt, `sltu, `sll, `srl, `sra, `and, `or, `xor, `nor
`define cal_ia `addi, `addiu, `slti, `sltiu
`define cal_il `andi, `ori, `xori
`define branch2 `beq, `bne
`define branch1 `blez, `bgtz, `bltz, `bgez
`define jump_i `j, `jal
`define jump_r `jr, `jalr
`define link `jal, `jalr
`define md `mult, `multu, `div, `divu
`define mf `mfhi, `mflo
`define mt `mthi, `mtlo
//about SrcBSel
case(E_order)
`cal_r : SrcBSel = SrcBSel_rtOut;
`cal_ia, `cal_il, `load, `store : SrcBSel = SrcBSel_EXTOut;
default : SrcBSel = SrcBSel_EXTOut;
endcase9.2 应试风格
事先声明,9.2节内容本人不负责任,因为阅读9.2节造成的一切后果,请自行承担!!!
谨慎阅读!!!
算了,奇技淫巧,登不了大雅之堂,不提也罢。
十、思考题
10.1 我们计组课程一本参考书目标题中有“硬件/软件接口”接口字样,那么到底什么是“硬件/软件接口”?(Tips:什么是接口?和我们到现在为止所学的有什么联系?)
我认为接口是解偶联和封装的关键,具体表现是一组需求,在大型项目中,不可能有人了解所有的细节,接口为分工合作提供了必要的支持,管理者通过规定接口,规定了需求和组织方式,这样才是高效的管理学。
对于软硬件接口,我觉得具体是一组约束,比如指令集,在软件方面就是汇编,在硬件方面就是译码,但是他们分别是建立在同一组规范中,再比如说中断,信号是硬件发出的,但是软件有负责了中断的处理。
10.2 BE 部件对所有的外设都是必要的吗?
我不太清楚系统桥的明确定义是什么,但是我觉得一个系统桥上既连接了DM这种需要快速交换的部分(甚至现在DM的大小和工作风湿,给人感觉想cache)这是北桥的工作,还连了定时器和外部中断信号(有些缓慢),这是南桥的工作。有点让人摸不着头脑。如果说系统桥的目的是片上通信的话,那么不是必要的。
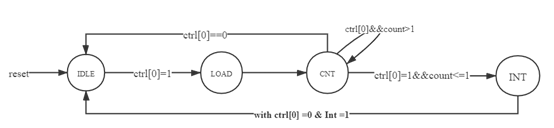
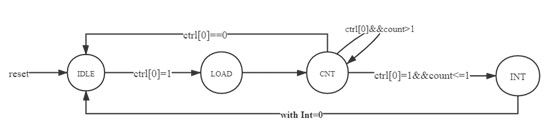
10.3 请阅读官方提供的定时器源代码,阐述两种中断模式的异同,并分别针对每一种模式绘制状态转移图。
中断模式0:将计数器写使能变为0,并且保持中断信号持续有效,直到计数器写使能为1。该模式通常用于定时中断。
中断模式1:只保持一周期的中断信号,并重新载入计数器初值,再次倒计时。该模式通常用于产生周期性脉冲。
模式0:
模式1:
10.4 请开发一个主程序以及定时器的 exception handler。整个系统完成如下功能:
(1)定时器在主程序中被初始化为模式 0;
(2)定时器倒计数至 0 产生中断;
(3)handler 设置使能 Enable 为 1 从而再次启动定时器的计数器。(2) 及 (3) 被无限重复
(4)主程序在初始化时将定时器初始化为模式 0,设定初值寄存器的初值为某个值,如 100 或 1000。(注意,主程序可能需要涉及对 CP0.SR 的编程,推荐阅读过后文后再进行。)
.text
addi $t0, $t0, 0xfc01
mtc0 $t1, $12 #给SR赋初值,IM全置1允许中断,属于初始化部分
li $s0, 0x7f04
li $s1, 100
sw $s1, 0($s0) #将preset赋成100
li $s0, 0x7f00
li $s1, 9 #即1001
sw $s1, 0($s0) #将Ctrl的IM位置1,说明允许中断,Mode置0,说明是模式0,Enable置1,可以计数
end:
beq $0, $0, end #这个必须要有,因为CPU会把xxxxxx识别成RI,然后就在异常里出不去了
nop
.ktext 0x4180
li $s0, 0x7f00
li $s1, 9 #即1001
sw $s1, 0($s0) #将Ctrl的IM位置1,说明允许中断,Mode置0,说明是模式0,Enable置1,可以计数
ERET:
eret
10.5 请查阅相关资料,说明鼠标和键盘的输入信号是如何被 CPU 知晓的?
键盘和鼠标本质上都是输入设备,其自身的内部有一些微处理器来控制自己与主机之间的信息交互。而在CPU看来,外部信号会经过很多层级传入到内部,而内部的信息也会经过很多层级传出至外部。这些层级由外至内大致可以分为主存->cache(->bridge)->CPU。
每个设备都需要驱动程序的,只不过驱动程序有的在电脑系统内,有的却需另外按装,比如:无线健鼠套装,驱动程序已经在USB头上,我们叫它免驱设备。如果没有这些指定驱动程序的话,电脑是无法识别内容的。
写在后面的话
P7真的是团队协作啊,所以郑重鸣谢:
- 代码次次无bug,环境次次无冲突:救命恩人,硬是把我的bug肝出来了
- ysy的迷弟:构造测试
- ysy的迷妹:构造测试
- ysy的迷:肉眼debug
- 我要早睡:督促我探究了wl的D级eret问题
- 小哥哥:肉眼debug
哄哄闹闹的一个学期都快过完了,之前数据结构助教问我,想去6系还是去21系,我说想去21系,他说是不是害怕6系太苦太累太被碾压,我说不是,我贱命一条,不值一提。关键是在6系,我没有把握护人周全,后来来了6系,确实,当时我第一次听冰哥给我介绍chgg的自动测试机的时候,我当时就傻了,这也太厉害了,P6之前,我每次上机之前都害怕,害怕自己的课下是有bug的,但是P6真的超级有安全感,因为我都过了P6的290条强测了。一想到上一届因为有chgg,那么这一级的同学多有安全感啊,这才是英雄!