一、线性规划(LP)
1.1 标准型
线性规划可以转化成标准型,但是可以发现有两种标准型,分别对应软件程序和数学形式,如下所示:
LP 求解器一般接口
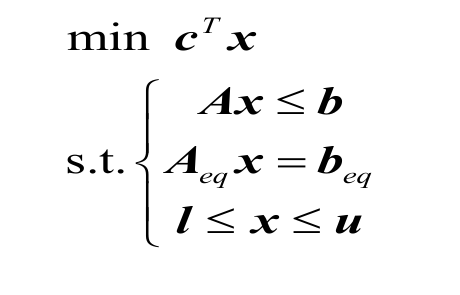
行列式(determinant)可以看做在多维空间上的向量组形成“有向体积”,这种认识可以辅助我们理解一些性质:
可以利用行列式求解四边形面积、六棱锥体积。
交换构成行列式的向量,并不会改变行列式的绝对值,而可能会改变行列式的正负。这是因为改变边的顺序不会影响体积。
一旦有一行或者一列为 0,或者这个方阵没有满秩,就会导致行列式为 0。某一个向量为 0,肯定会导致体积为 0,当没有满秩,就说明有两条“边”方向重合了,也会导致体积为 0。
将一行(列)的 $k$ 倍加进另一行(列)里,行列式的值不变。类似于固定了底面和高,其实第三条楞只要在平行于底面的边上变化,就不会导致体积的改变
在行列式中,某一行(列)有公因子 $k$,则可以提出 $k$。类似于一条边的倍数发生变化的时候,会导致体积的倍数发生相同的变化。
运行时存储组织与管理要回答的问题是
函数在内存中是如何表示的
他们在内存中如何放置,如何管理(这里面有个专题是垃圾回收机制)
.data 的处理
需要压缩文法包括两种: