REEF:为并行 DNN 推断设计的抢占调度
一、问题描述
1.1 基本认识
进程调度的本质是对于计算资源的分配,被调度到的进程拥有计算资源,就可以更快地完成自己的计算任务。不同的调度策略会使得计算系统呈现不同的效果,非独占式的轮流调度会使得每个进程的等待延迟减少,同时提高系统的并行度,进而提高吞吐量,但是会提高任务完成的延迟;独占式的串行调度,会让进程在运行时独占所有资源,可以降低任务完成的延迟,但是会增加任务的等待延迟,同时降低系统的吞吐量。
进程调度策略没有“银弹”,任何一种调度策略都会存在一定的优势和劣势,重要的是如何结合设计需求,选择并实现更能满足目标的调度策略。
1.2 矛盾分析
在许多深度神经网络(DNN)的应用场景(比如说自动驾驶)中,我们可以将 GPU 上的进程(也可以被叫做“任务(task)”或者“核函数集合(kernels)”)分为两类:一种是“实时任务(Real Time,RT)”,它对于延迟是敏感的,完成这个任务的等待时间不能很长,比如说自动驾驶系统中识别障碍的程序,显然不能等车已经撞上了障碍物,GPU 才识别出这个障碍物并做出闪躲的指令。另一种是“尽力交付的任务(Best-Effort,BE)”,这样的任务对于延迟并不敏感,等待较长的时间并不会影响任务的质量,比如说监视司机情绪和疲劳的任务,即使等待稍微长一些的时间,也并不会引发安全事故。
对于一个理想的 GPU 系统,我们有两个目标:希望所以递交给它的 RT 任务,都能低延迟的完成,同时我们希望 GPU 尽可能“多”的处理任务,也就是说,我们希望 GPU 维持一个高吞吐量状态(也可以叫做“work-conserving”策略),这需要 GPU 并行运行多个任务(因为只有同时运行运行多个任务,才能充分利用 GPU 的计算资源)。
但是这两个目标是在现有设计下是矛盾的,高并发意味着同时有多个进程在运行,这不仅会降低正在运行的 RT 的完成时间(因为多个任务在共享 GPU 的计算资源),而且会增加即将到来的 RT 的等待延迟(因为要等待排队)。
那么这个问题是否是无法解决的呢?其实是有的,那就是抢占式调度,在 RT 任务到达的时候,立刻将进程切换成这个 RT 任务,当这个任务结束以后,再执行那些延迟不敏感的 BE 任务。那为什么这么直观的方法,没有人设计实现呢?这是因为 GPU 由于大量并行的特性,它的上下文是极其庞大的,所以切换上下文的开销是巨大的。所以 GPU 进程切换,常常发生在一个 kernel 结束的时候,所有用于这个 kernel 计算的上下文都失效了,此时切换的代价会较小。但这样是无法满足“实时”的需求的。
所以这个问题的核心矛盾是:对 GPU 兼顾实时性和高吞吐量的要求与 GPU 高昂的进程切换代价之间的矛盾。不得不承认,这个矛盾是没有办法轻松调和或者解决的。它反应了一种 GPU 架构中由于并行带来的笨拙“惯性”与需求的精妙的矛盾。
1.3 抽象模型
为了更好地分析问题,我们来介绍一下此篇论文对于问题的抽象描述,它将任务(其实比叫“进程”要更好,因为运行在 GPU 上的东西并不具有完整的声明周期,它只是一个具体的任务而非进程)抽象成如下图所示的结构
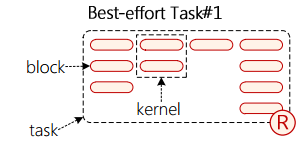
一个 task 由多个横向排列(也就是按时间顺序排列)的 kernel 组成,一个 kernel 由一列 block 组成(也就是需要部署在不同的计算单元 CU 上的小东西)。这里它简化了 GPU 的硬件结构,认为不同的 block 是部署在不同的 CU 上的,而且调度的最小粒度就是 block,这些都是不太准确的,不同的 block 是可以部署在同一个 CU 上的,调度的最小粒度不是 block 而是 warp,但是这种有损进度的抽象并不会妨碍理论的推导,这是因为即使多个 block 部署到同一个 CU 上,也是硬件调度的分时复用,和一个“独占一个更弱的 CU”类似,block 只是在概念上比 warp 大一些,并没有实际的区别,完全可以将 warp 视为一个 block。
由上图可以看出,不同 kernel 对于 CU 的占用是不同的,有些 kernel 用了 4 个 CU(第 1,4 个),但是有的 kernel 只用了一个 CU(第 3 个),用 CU 较少的 kernel 可以将剩下的 CU 分给其他 kernel,这是一个提高吞吐量的方法。
我们将延迟分为以下几种,如图所示:
总延迟(overall latency):指的是从第一个任务开始,到最后一个任务结束的时间。它是“吞吐量”的一种量度,它减小表示吞吐量的增大。
抢占延迟(preemption latency):指的是某个任务到达到这个任务被调度之间的时间间隔。它是“实时”的一种量度,它增大说明实时的失效。
端到端延迟(end to end latency):指的是某个任务到达到这个任务结束的时间间隔。它也是“实时”的一种量度,它增大说明任务需要更多的时间才能结束。
执行延迟(excute latency):任务的实际执行时间,一方面是为了说明原有的抢占式调度会让抢占时间变得难以容忍,有如下等式:
另一方面是为了方便之后的调度,也就是根据 BE task 的执行时间去进行 padding。
1.4 现有方法
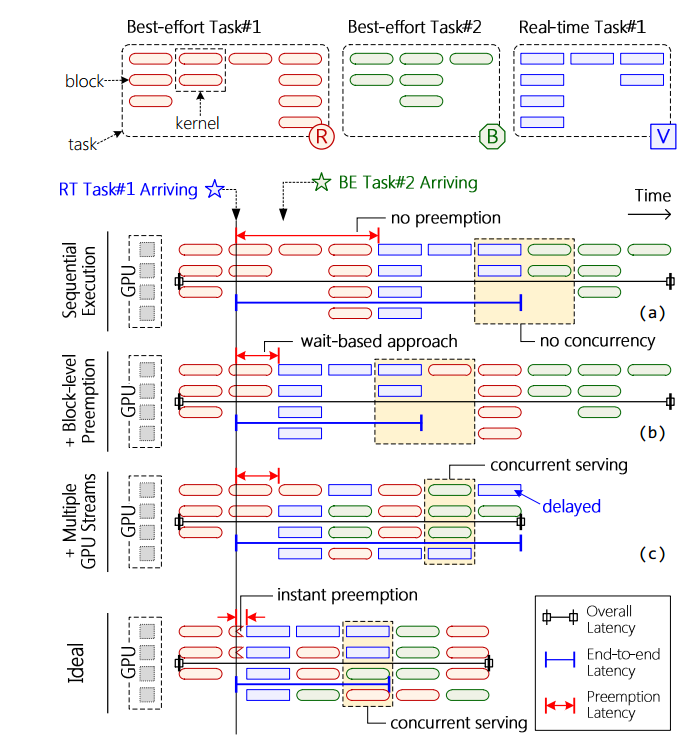
不同的调度策略直观图如下:
1.4.1 串行执行
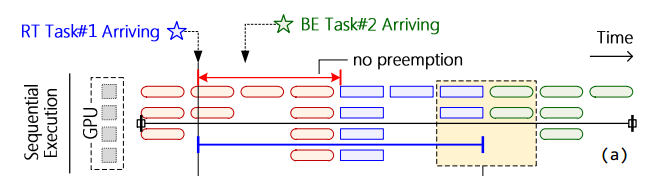
其调度示意图如图(a)所示:完全按照到达时间进行调度,RT 并不进行抢占,所以只要前面有大量的 BE 任务,那么就会导致 RT 的抢占延迟极大。同时,也可以看到,这是一种独占式的调度策略,所以不同 kernel 是不能并发的,所以这种存在一定的吞吐量问题。
这种策略是一般商用的通用 GPU 采用的策略。至于为何商用 GPU 会采用这种策略,可能是因为商用 GPU 不能保证每个时刻都有多个 kernel 方便它并发。也就是处于“通用”的目的,采用了较为朴素的方式。
1.4.2 多 GPU 流
目前提供的 GPU 库确实可以提供共享服务,也就是由图(C)展示的,不同的 kernel 是可以并发的,这时 overall latency 缩小,系统的吞吐量增大。但是由下图可以看出,当引入较多的尽力交付任务时,实时任务的尾部延迟(尾部延迟是高百分点的延迟,代表响应时间超过服务或应用程序处理的所有请求的98.xxx-99.xxx%的请求)会几何倍的增加:
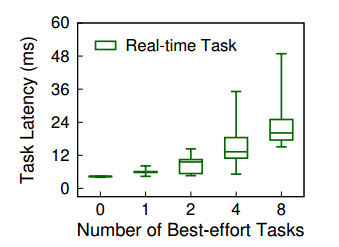
尾部延迟过长会危害实时任务的稳定性和可信赖性。
尾延迟的增加,是因为共享导致真实分给 RT 的计算资源被稀释了,执行时间增加了,可能要很靠后的时间才能完成。
1.4.3 基于等待的抢占
这是之前学界提出的抢占策略,当一个 RT 任务来临时,会进行抢占,将任务切换成当前的 RT 任务。但是发生切换的时机并不是立刻切换,而是需要等待当前 kernel 运行结束之后才可以进行抢占,如图(b)所示。这样依然会有一些抢占延迟,而且有统计图如下:
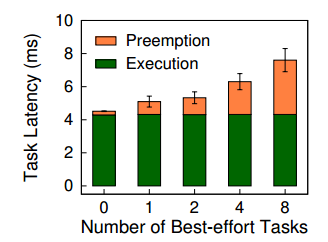
可以看到当 BE 任务增多时,抢占时间也会增加,这会导致不符合“实时”的要求。
三种方法的对比如下表所示:
| 调度方法 | 吞吐量 | 抢占延迟 | 尾延迟 |
|---|---|---|---|
| 串行执行 | 小 | 大且不稳定 | 小 |
| 多 GPU 流 | 大 | 适中 | 大 |
| 基于等待的抢占 | 适中 | 适中 | 中 |
可以看到基本上没有任何一种现有的方法是十分理想的,都有着这样那样的缺陷。
二、设计实现
2.1 具体分析
在普世的情况下,对 GPU 兼顾实时性和高吞吐量的要求与 GPU 高昂的进程切换代价之间的矛盾是没有办法解决的,但是如果具体到 DNN 推断的背景中,则是有可能解决的。
对于 DNN 推断,有如下特点:
2.1.1 幂等性
因为 DNN 的核都是一堆稠密线代计算,所以是幂等的,即特定输入对应特定输出,是没有状态的(突然想到跟 http 的设计很类似)。DNN 的某一层的输出同时还一般只依赖于前一层的输入和一些静态参数。这种良好的性质使得任务的上下文的保存和恢复变得没有意义,对于无法恢复的上下文,我们直接不恢复了,而是重新运行这个 kernel,这样就节省了保存和恢复上下文的开销。
2.1.2 多个核函数
现在的 DNN 模型都会有很多个核函数,并且一并提交给 GPU(增加吞吐量),所以 GPU 一般会并发运行多个核函数。也就是说,同一个时间内,GPU 上有多个核函数可以进行调度和并发。
这是一个很有利的条件,这使得我们在进行并发的时候,有更多的选择。只要选择得到,就不会出现 GPU 空转的情况,因为现在是“供大于需”。
2.1.3 可预测的执行时间
因为核函数中没有分支和循环,并且矩阵的大小是固定的,所以执行时间是很好估计的。
这点如果和“多个核函数”的优点结合起来,那么就是说,有一堆十分可以控制的 kernel ,这些 kernel 可以为并发创造更好的条件,这两点提供了一种被叫做“动态补全”的调度机制,可以极大地提高 GPU 的并发性。
在有了这三个特性的基础上,矛盾并非不能转化和解决的。
2.2 技术群
不同于一些论文的写作思路,这篇论文并没有“提出一个技术,论证用这个技术可以解决诸多的问题”,而是“为了解决某个问题,提出了一堆技术”,这使得出现在本文的技术十分繁多,很容易让人眼花缭乱。这也就是所谓的“方法导向”和“研究导向”之间的区别。
在介绍诸多的技术细节前,我们需要梳理出两条技术的主线,这两条主线分别对应两个设计需求:
- 保证 RT 的低延迟:开发了基于重启的抢占式调度,这个技术有可以具体分为重启缓存核函数,重启运行核函数,恢复中断函数,在闭源 GPU 上的替代方案 4 个部分。
- 高并发,高负载,高吞吐量:开发了动态补全技术,这个技术主要由两个部分,一个部分是动态 dkp 的实现,它实现难度上主要是间接函数调用开销过大和动态寄存器过分配问题,分别针对这两个难点,开发了全局函数指针和 CU 占有率代理两个技术,这两个技术都是从编译角度解决问题。另一个部分是补全 kernel 的选择策略。
2.2.1 基于重启的抢占调度
核函数的生命周期和运行环境
首先我们需要了解核函数的生命周期,才能更好地了解我们实现抢占式调度需要解决的问题。对于核函数的部署,如下所示
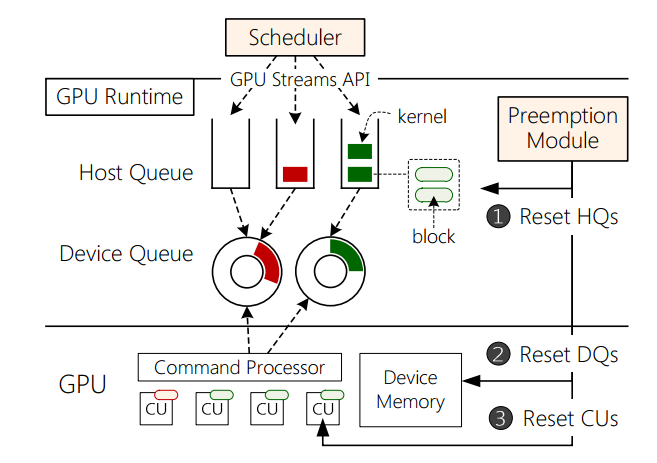
在 CPU 侧有 GPU runtim,会将不同的 kernel 分发到不同的 Host Queue 中,Device Queue 作为 CPU 和 GPU 的交互地带,kernel 会分别被入队和出队。然后 GPU 将出队的 kernel 部署到 GPU 的 CU 上。
另外说一嘴,这里涉及了一个 GPU Stream 的概念,它可以提高 GPU 的并发度
NVIDIA 家的 GPU 有一下很不错的技能:
- 数据拷贝和数值计算可以同时进行。
- 两个方向的拷贝可以同时进行(GPU 到 CPU,和 CPU 到 GPU),数据如同行驶在双向快车道。
但同时,这数据和计算的并行也有一点合乎逻辑的限制:进行数值计算的 kernel 不能读写正在被拷贝的数据。
Stream正是帮助我们实现以上两个并行的重要工具。基本的概念是:
- 将数据拆分称许多块,每一块交给一个 Stream 来处理。
- 每一个Stream包含了三个步骤:1)将属于该 Stream 的数据从CPU内存转移到 GPU 内存,2)GPU 进行运算并将结果保存在 GPU 内存,3)将该 Stream 的结果从 GPU 内存拷贝到 CPU 内存。
- 所有的Stream被同时启动,由GPU的scheduler决定如何并行。
GPU stream 的实现应该跟 GPU runtime 中的两种队列结构有关。
从图中可以看出,当发生抢占的时候,我们需要清空 Host Queue,Device Queue(在这些结构中的核函数统称为“Buffered Kernel”),同时还需要清空正在运行的核函数。被抢占的核函数,我们在 RT 任务结束之后,还需要重新运行被抢占的 BE 任务。
清空 buffer kernel
Host Queue:可以直接更改 Host Queue 的指针(也就是替换上一个新的 Host Queue),但是原有的 Queue 就需要回收,我们采用一个后台垃圾回收线程来异步完成内存回收,相比于串行回收,提高了效率。
Device Queue:因为处于 CPU 和 GPU 的交互地带,所以并不能简单的换一个内存接着搞(会存在一致性的问题),所以需要更加细致的对待,为此我们开发了两个技术:
- 懒驱逐(lazy evicte):通过注入源码,让每个 kernel 最前方有一个对于抢占 flag 的检测,当抢占发生时(检测到 flag 为真),被抢占的 kernel 依然会被发送给 CU,但是会立刻终止自己。
- 限制队列容量:懒驱逐只是保证对于被抢占的核函数不会被执行,但是抢占核函数需要等这些“僵尸核函数”都运行完,才能轮到自己运行,这会造成很大的延迟。所以最好的方法是限制队列容量到一个较小的数值,这样排在前面的“僵尸核函数”就不会过多。
杀死正在运行的核函数
在 GPU runtim API 并没有显式的提供这个功能,但是实际上对于 GPU 终止运行的任务的 API 稍作修改,就可以获得这个功能:新函数将指示命令处理器杀死CU上所有正在运行的内核,但在GPU内存中保留它们的运行状态。
恢复被抢占的任务
在抢占发生时,其实我们并不知道到底哪个核函数正在运行,这是因为 GPU 负责去 Device Queue 去取 kernel,所以在 CPU 侧并不清楚到底 GPU 取了哪个(它只负责放 kernel)。所以当我们恢复时,会这样处理:
在清空队列的时候,可以知道 device queue 的队尾是哪个 kernel,然后我们从队尾往前数 c 个(c 是队容量)核函数来执行。这是因为队内的核函数可能被执行,也可能不被执行,这样做肯定没有问题。
闭源 GPU
闭源 GPU 不可以修改 runtime,所以对于上面的诸多技术,需要进行补丁处理:
- Host Queue:单独提出一个 vHQ 来代替 Host Queue(英伟达的两个 Queue 并不暴露接口)。
- Device Queue:将整个 GPU runtime 视为多个 Device Queue(每个 GPU stream 对应一个)。
- lazy evicte:并不会受到影响。
- 限制队列容量:因为无法修改 GPU runtime,所以改成限制 vHQ 发射的数目。
2.2.2 动态补全技术
静态融合技术
将多个核函数进行融合,这样一个“融合核”就可以更好地利用 GPU 的计算资源,提高了 GPU 的并发性。论文说并不适合,因为 DNN 的核函数很多,所以需要在编译时完成的静态融合会耗费大量时间,不太现实。
我个人觉得是因为 RT 的到达是随机的,所以并不能确定 RT 到底要和哪些 BE 进行融合,所以就没有办法使用这种技术了。或者需要把所有的可能情况都考虑到。
动态补全技术
动态补全技术是我们的改进方案,利用一个动态模板(dkp)来提高并发性,dkp 上可以“装载上”一个 RT 核函数和多个 BE 核函数,“装载”是发生在运行时的,根据编译期收集的 profile 决定。但是这个设计思想依然有很多的问题需要解决。
改造函数指针
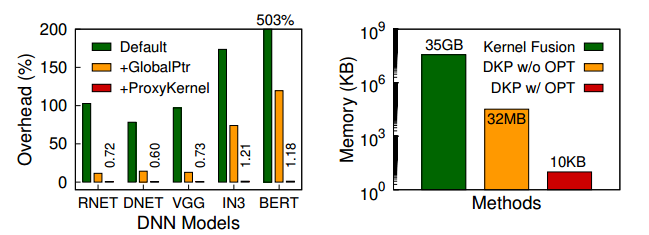
按照原本的设计思路,dkp 装载任务应该通过函数指针实现的,从本质来说, GPU 的函数指针是 device 性质的,也就是为了可以被 GPU 函数调用(更加侧重于 GPU)。这种性质的函数指针并不好,是因为函数指针是没有办法进行函数内联优化的,而 GPU 调用函数时需要保存大量的上下文,这就会加重开销。此外,因为函数指针的不确定性,GPU 倾向分配更多的寄存器来满足一个未知函数的需要,所以这无疑更加加重了开销。所以我们需要对于原始的函数指针进行改造。
针对第一个问题,我们使用全局函数(global function)指针,这里说的“全局”,并不是 C 语言中“在数据区的函数指针“,而是“全局函数”作为一个概念,由 __global__ 修饰,表示由 CPU 调用,交给 GPU 完成的任务(也就是说,kernel 都是 global function)。这种函数可以看做是一种和 C 语言 main 函数类似性质的函数,正是因为如此,所以在调用 global function 的时候,是不需要保存上下文的(保存谁的上下文呀),只是原本 global function 只能调用 device function,无法调用 global function,所以我们修改汇编,直接将 call 改成 jump 。
针对第二个问题,不确定性是无法消除的,但是我们可以利用代理函数按照资源的占用率来分类这种不确定性。代理函数类似于一种资源占有的模板,他和 dkp 有着一样的源码,只是具有不同的资源占有率(比如说寄存器数量和共享内存数量),这样可以避免 dkp 的寄存器的过度分配。在具体实现层面,似乎是通过修改汇编来实现的。通过字符串处理脚本将不确定的寄存器修改成确定的寄存器。
补全核函数的选择
在解决了 dkp 的实现问题以后,需要考虑补全函数的选择问题。我们的原则是“BE 核函数只能使用 RT 核函数剩下的资源”,这样可以最大程度保证 RT 任务的实时性。
但是这个原则其实并不能准确地指导内核的选择,本文选择了一种较为保守的启发式原则:
- BE 的执行时间一定要比 RT 的执行时间短。
- BE 的 CU 占有率要小于 RT 的 CU 占有率。
这是一个很保守的策略,因为能同时满足这两条的 BE 核函数并不是很多。但是却能很好的保证 RT 核函数一等公民的地位。
2.3 项目架构
项目的整体架构如下图所示,可以看到分成了离线部分(offline)和在线部分(online):
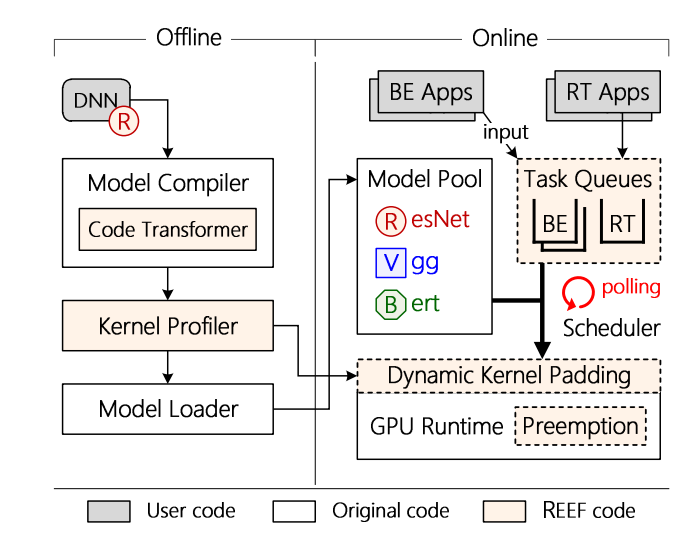
2.3.1 离线部分
离线部分运行在模型的编译期,主要分为两个部分:
- code Tranformer:通过拓展 TVM,增加 code transformer 模块,来检验核函数是否具有幂等性,并转变其源码方便 GPU 的调度。在实际实现中,应该是位于
reef/script中,有一些手段是字符串处理。 - kernel profiler:测量模型的执行时间和对于计算资源的需求。
2.3.2 在线部分
在线部分运行在任务的运行期,主要由以下几个部分组成:
- 任务队列:具有一个实时应用队列和多个尽力交付队列,每个队列对应 GPU 的一个流
- 调度器:会采用轮询的方式从任务队列中取出任务,具有实时模式和普通模式两种模式。在普通模式下,似乎就是默认使用 cuda 的库(可能就是 GPU runtime)在实时模式下,就会立刻抢占调度。
三、实验评估
3.1 DISB
本文仿照 YCSB 开发了新的 benchmark DISB,具有 5 种有特色的负载,如下表所示:
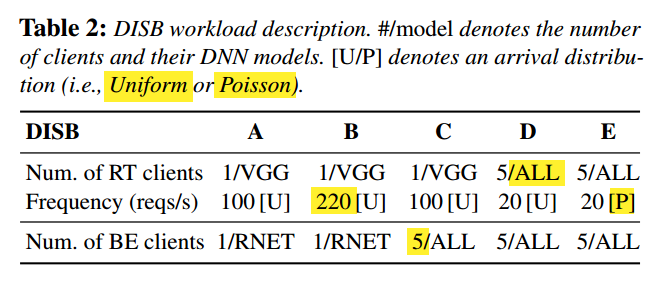
除了 benchmark 之外,本文还准备了从真实自动驾驶平台(Apollo)上收集的工作集。
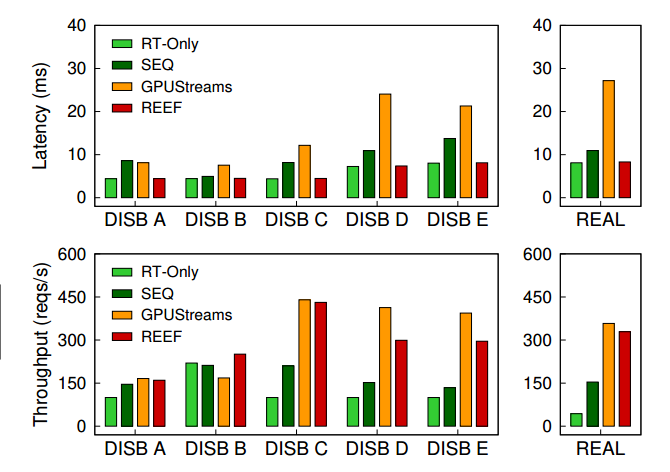
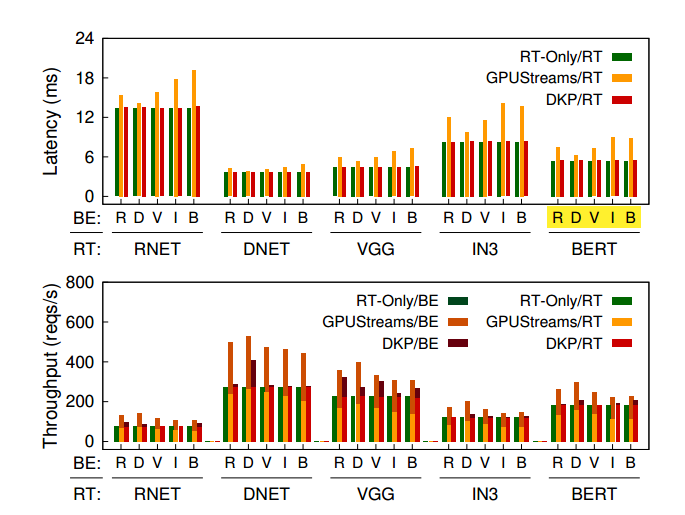
在实验中,我们设置了多个对照组,其中RT-Only 策略是 RT 延迟的极限,因为只执行 RT 任务,GPUStreams 应该是吞吐的极限,因为是官方库组织的并发。
3.2 总体表现
对于只有一个 BE client 的情况(也就是 A, B),因为 BE 的请求不多,所以 GPU 并不拥塞,不同的之前的调度策略的总体性能表现差不多,比如说 SEQ 的延迟很低,GPUStream 的吞吐量很高。但是只有 REEF 兼顾了二者的优势。
当存在多个 BE client 的情况(C,D,E),随着 BE 请求的增多,GPU 出现拥塞,GPU stream 的处理 RT 任务的延迟会极大的提高,而 SEQ 的吞吐量会有一个下滑,只有 REEF 依然发挥稳定。
在真实世界负载中,RT 任务的频率会更低,scheduler 会基本上一直维持 normal mode,这个状态和 GPUSteam 类似。
3.3 抢占式调度
这里主要做了两组对照实验:
3.3.1 两种抢占方式
首先对照了基于等待的抢占式调度和基于重启的抢占式调度,本文先是在 DISB 五种负载上进行了测试,然后再不同的 DNN 网络上进行了测试,基于重启的延迟要明显低于基于等待的延迟,对照结果如下:
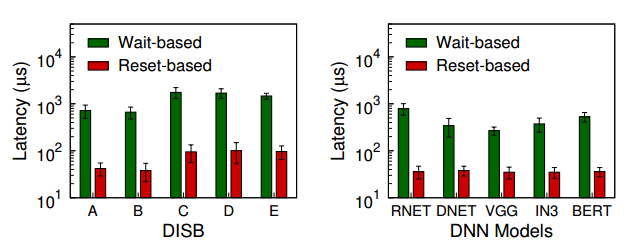
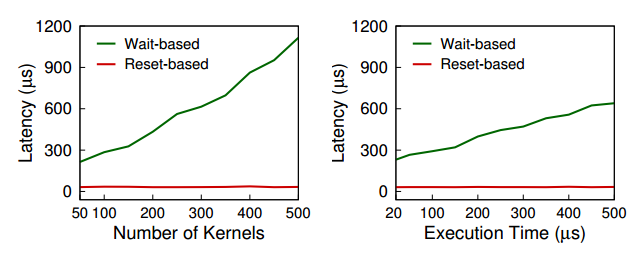
然后我们进一步探究了为何这两种方式存在差异,可以看到当核函数数量增多或者执行时间提高时,基于等待的抢占调度都会有较差的性能表现(本来就是基于等待的抢占式调度不太适应的场景)
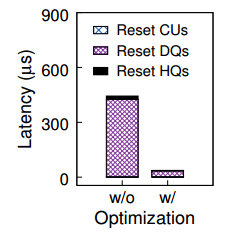
3.3.2 有无优化
其次对照了无优化的基于重启的抢占调度与有优化的调度,优化项包括异步内存回收和队列容量限制。优化过后效果会显著提高,图示如下:
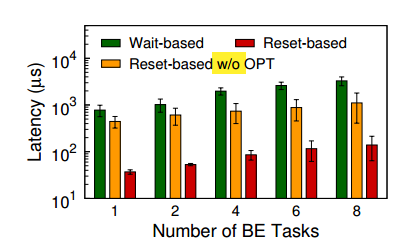
究其原因,是因为 Device Queue 的清空十分耗时,这两个优化都可以减少清空需要的开销,如下图所示
3.4 动态核函数补全
3.4.1 补全技术
当 BE 负载过大的时候,可以看到只有 GPUstreams 保证了吞吐量,RT 有一定的衰减,这是因为我们的补全策略比较保守。
3.4.2 有无优化对比
优化主要设计全局函数指针和代理函数两个部分,其效果都是十分显著的: