Linux - 编译工具
一、gcc
1.1 一步到位
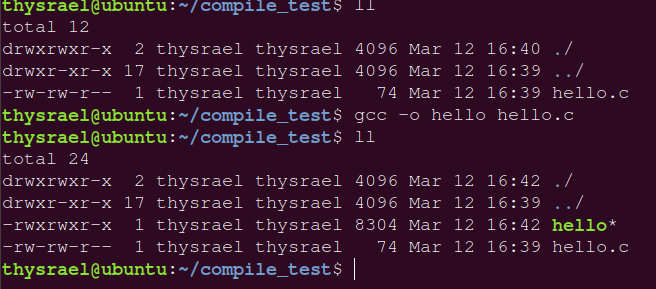
gcc 最简单的用法
gcc c_name.c # 会产生一个 a.out 的可执行文件 |
这样会生成一个叫做 a.out 的可执行文件。
如果想要指定生成文件的名字,可以采用 -o 选项,也就是 output。比如下面的指令
gcc -o hello hello.c |
这个 -o 参数可以跟在后面讲的所有指令后面,也就是说,可以给所有生成的中间文件进行命名。
如果想要最佳化执行速度,可以使用下面的命令:
gcc -O c_name.c |
可以根据操作环境最佳化执行速度
如果想要显示警告信息,可以用 -Wall 参数,如下
gcc -o hello hello.c -Wall |
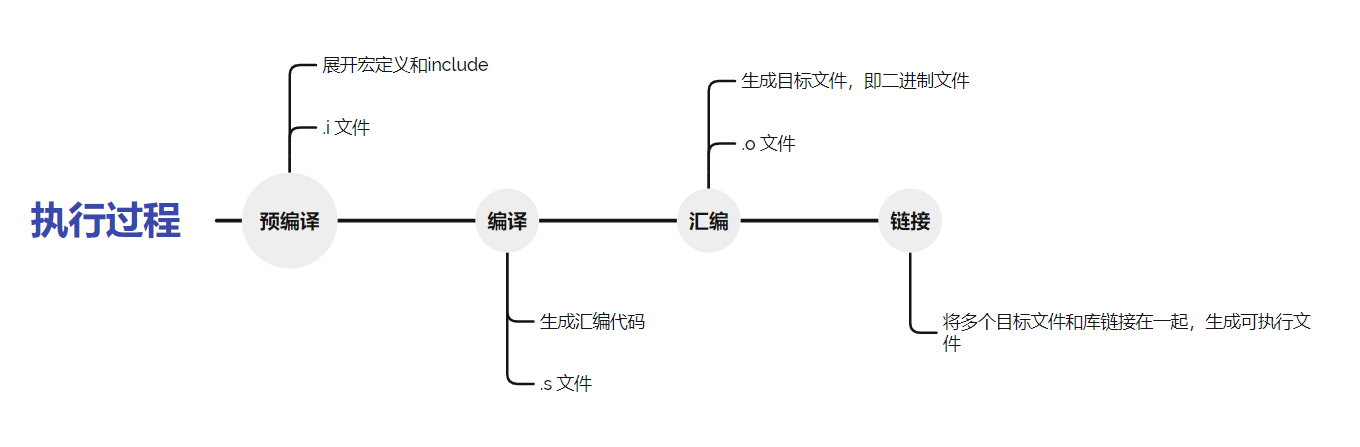
这样一步到位,似乎只能适用于比较低端的情况,如果想要更细致的操作,需要了解整个编译的流程,即图:
1.2 预处理
在这个过程就是展开宏定义和 include 文件,可以使用如下命令
gcc -E c_name.c |
但是直接使用这条命令,不会生成一个 .i 文件,而是将展开结果直接输出到终端,所以得指定一个名字
gcc -E c_name.c -o i_name.i |
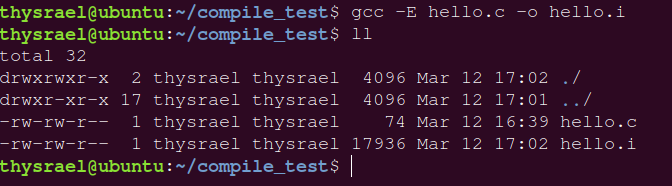
生成完的文件会特别丑,大概这样:
在这里,我们还有一个问题,就是头文件在哪里,我们系统一般会把头文件存在 /usr/include 下( /usr 不是 user 的缩写, 其实 usr 是 Unix Software Resource 的缩写, 也就是 Unix 操作系统软件资源所放置的目录, 而不是用户的数据; 所有系统默认的软件都会放置到 /usr),这个文件夹长这样,里面有我们常用的头文件
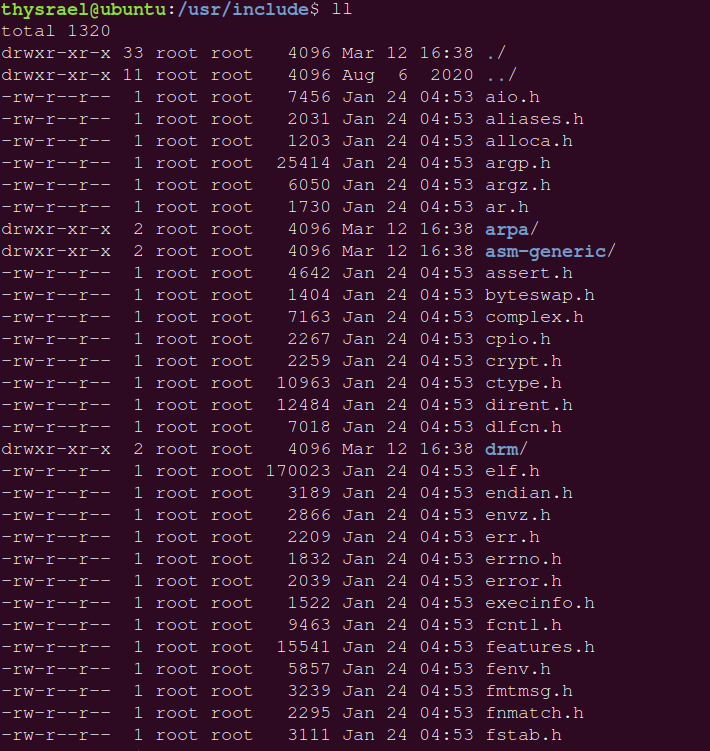
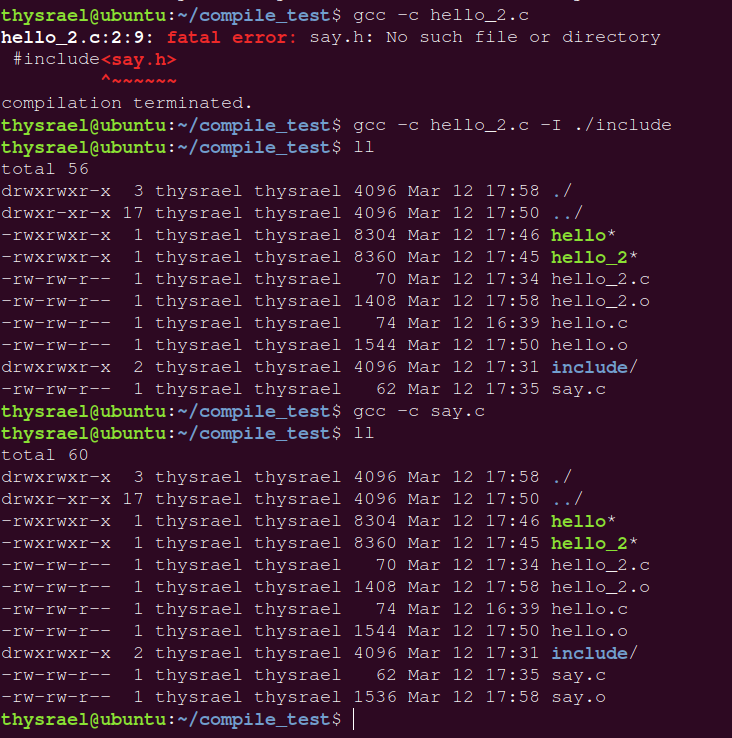
当然我们也可以使用指令来指定我们的头文件:
gcc c_name.c -I head_path |
为了演示这个功能,我们在我们的工作目录下创建是三个文件,一个文件夹,如图
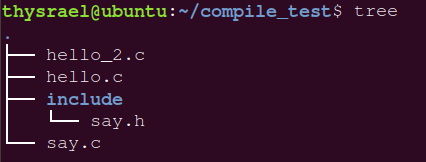
其中 hello_2.c 中内容如下
|
say.c 中内容如下
|
say.h 中内容如下
|
如果直接编译,会发现会报错

这是因为没有找到头文件,所以我们需要用 -I 参数来选择我们自己的头文件
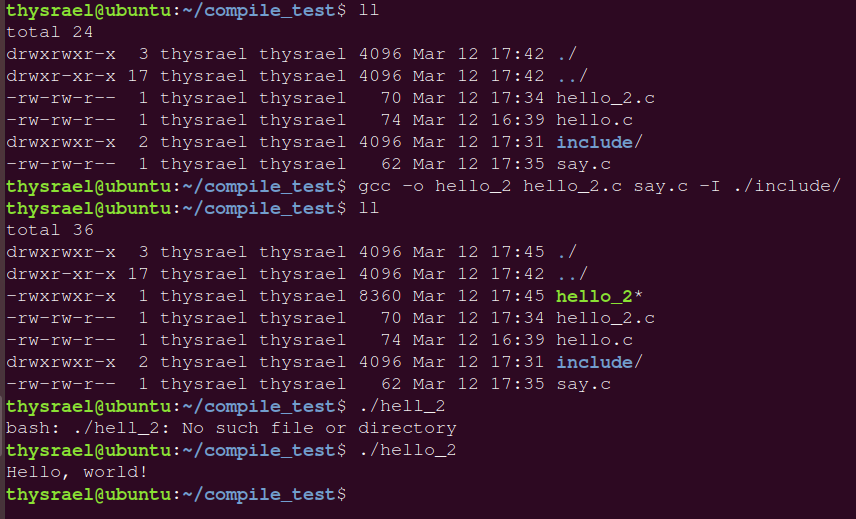
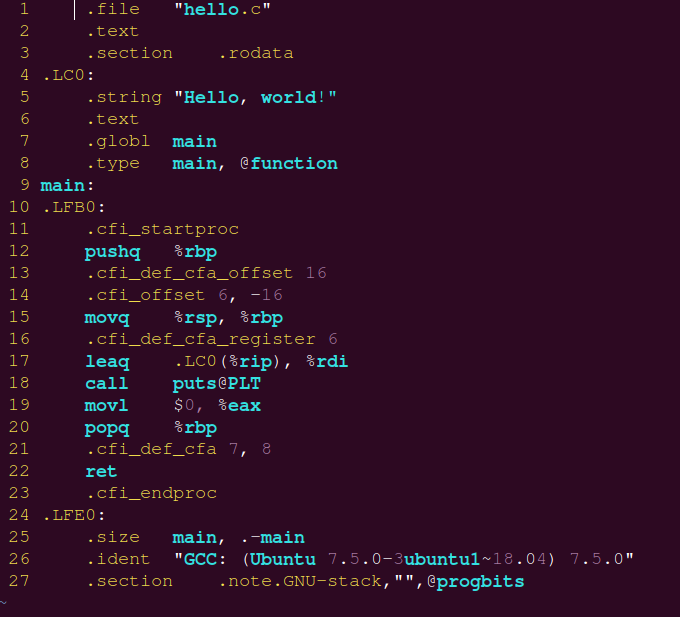
1.3 编译
编译就是将高级语言生成汇编代码的过程,有如下命令
gcc -S c_name.c |
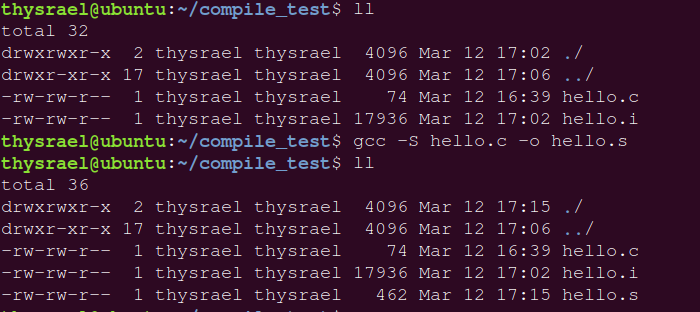
汇编代码长这样:
1.4 汇编
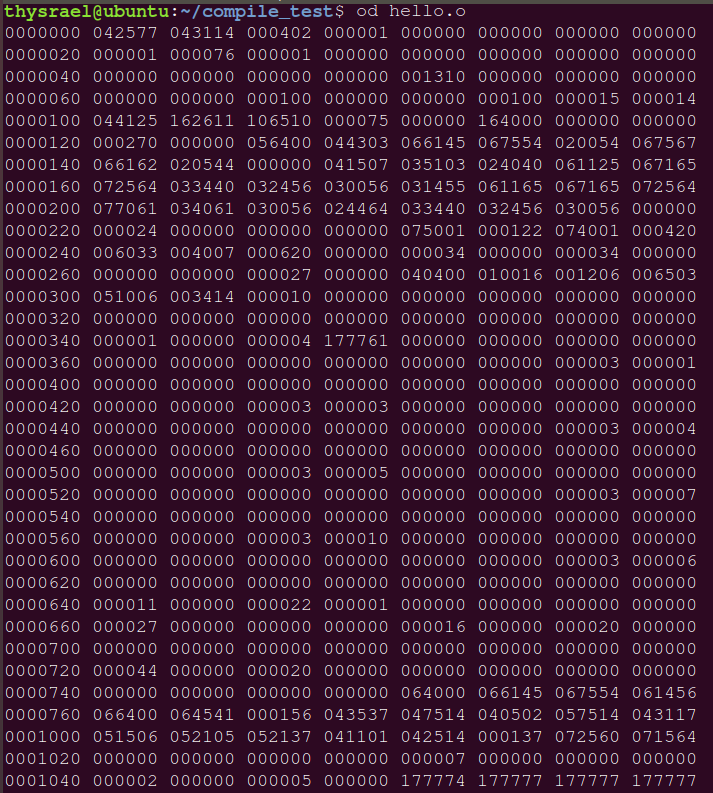
进行汇编可以生成 ELF 格式目标文件,命令为
gcc -c c_name.c |
这条命令后会生成 c_name.o ,此时已经是二进制文件了,所以不能用 vim 查看,而改成用 od 命令进行查看,如图
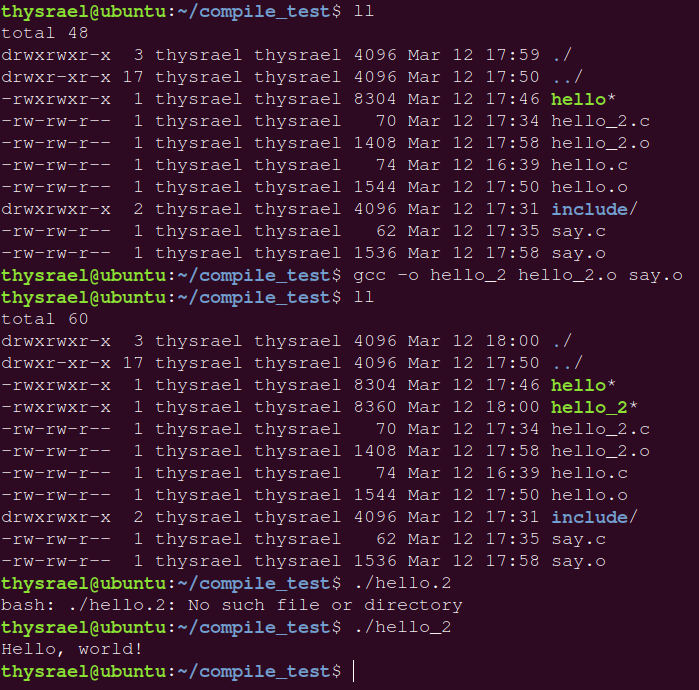
1.5 链接
链接是将多个目标文件和库链接到一起,生成可执行文件的过程,由下图可以看到,目标文件不具有可执行权限(就是没有 x )

这里我们还是用 hello_2 来举例,因为它是一个多文件项目,我们编译出目标文件
然后进行链接
链接的时候会用到库文件,系统默认的库文件是在 /lib ,库文件分为静态库和动态库,静态库和动态库的区别体现在程序的链接阶段:静态库在程序的链接阶段被复制到了程序中;动态库在链接阶段没有被复制到程序中,而是程序在运行时由系统动态加载到内存中供程序调用。后缀与库文件对应关系
| 类型 | Linux | Windows |
|---|---|---|
| 静态库 | .a |
.lib |
| 动态库 | .so |
.dll |
库文件目录大概长这样
库文件同样是二进制文件,大概长这样
我们同样可以指定查找库的目录和特定的库,但是因为我不会写库文件,所以就没有示例了
gcc sin.c -lm -L/lib # 调用 libm.so 或者 libm.a,库的索引目录是/lib |
其中 -L 说明了库文件的索引目录,-l 说明了调用的库。
说道最后,介绍一下标准操作格式:
gcc -o ELF_name object1.o object2.o |
1.6 反汇编
objdump 是用查看目标文件或者可执行的目标文件的构成的 gcc 工具。有如下参数
--archive-headers |
二、make
2.1 基本原理
代码变成可执行文件,叫做编译(compile);先编译这个,还是先编译那个(即编译的安排),叫做构建。Make 就是一个帮助我们进行构建的程序。这个程序需要以一个叫做 Makefile 的文件作为输入。
关于具体的工作流程,我觉得应该是 Makefile 起到一个类似与脚本(与 bash 的语法很像)的作用,而 Make 作为一个脚本解释器,可以去执行 Makefile 中的命令。
那么为什么不直接写脚本呢,这是因为 make 的优势在于,他并不是每次都执行所有的命令(对于只修改了一个源文件的项目,将整个项目都编译一遍,过于大费周章)。而是只会编译相对于前面项目有改变的文件。
2.2 基本格式
<target1> : <prerequisites1> |
2.3 目标
其实 Makefile 更像是一种脚本的集合,每个目标其实可以看做是一个脚本,当我们使用命令
make someTarget |
的时候,其实就类似于调用了 target 对应的脚本。
此外,如果直接输入命令
make |
那么就执行第一个目标。
2.4 依赖
依赖,即 prerequisites。我们在 2.1 提到的编译变动的功能,是通过依赖来实现的,make 某个目标前,make 会检验该目标对应依赖的时间戳,如果发现距离上一次编译有改动,那么就重新编译。所以依赖不是真的依赖,而是一个检验记号,比如说这样的写法

尽管我理论上需要依赖 hello_2.c, say.c, ./include/ 文件,但是我不写,它照样能跑。
2.5 命令
正是因为 make 的大部分语法与脚本相像,所以注释,通配符,变量赋值就不写了,我在其他博客里写了。在这里主要讲一下自动变量(Automatic Variables)
$@ # 即当前的 target |