一、总论
1.1 硬件术语
为了不让读者懵逼(主要是我自己也懵逼),所以特地整理一下在后面会用到术语。
我们电脑上有个东西叫做内存,他的大小比较小,像我的电脑就是 16 GB 的。它是由 ROM 和 RAM 组成的(“组成”可能不太严谨)。他也被叫做主存,我们为了访问他,所以需要给他的存储空间进行编号,这种编号被叫做物理地址。
我们电脑上还有个东西叫做外存,他的大小比较大,像我的电脑是 256 GB的。它可以是磁盘,也可以是固态硬盘,还可以是 U 盘。我们访问它,也是需要对它的存储空间进行编号的,拿磁盘举例,我们一般用“分区-扇区”的系统来描述我们在访问磁盘的哪个区域。总之它是一个不在这一章重点讲的东西。
1.2 盲人摸象
内存管理一直是一个很困扰我的知识,我从上个学期学计组的时候开始接触,课上就很好好听了(主要是跟 cache 对照着理解),然后为了备考又复习了一遍,但是就说要把理解透彻的东西写下来,后来因为时间关系就鸽了。如今学操作系统,还没有进入这一章的时候,各种概念就铺面而来,也是手忙脚乱。
我觉得现代的内存管理之所以难以理解,是因为它是一个整体的、多功能的管理系统。多功能就导致很多时候,我们往往抓着其中一个功能来谈,然后就根据这一个功能来定义内存管理了。其实这就是盲人摸象的一种现象,人们在描述内存管理的时候,往往只说他的一个功能,比如说
“我们为什么要内存管理呀?因为访问磁盘太慢了,我们将内存作为磁盘的缓存,就可以提高访问速率了。”
“我们为什么要内存管理呀?因为内存空间太小了,可能容纳不了一个进程,所以我们就需要内存管理。”
“我们为什么要内存管理呀?因为要给每个进程提供一个独自占有存储器的假象,所以我们就需要内存管理了。”
这三句话是没有错误的。但是他们都没有看到内存管理系统的全貌。或者说他们明明看到了全貌,却只愿意用一种观点去解释。比如当我们认为内存管理是为了提高访问速率,那么我们看见什么页式的,就会认为页就是 Cache 中的 Cache line。也不能说不对,就是页式管理的本质不是为了干这个的,只能说它只是在完成它的主要功能后,捎带手符合了一种牵强的解释。
这是一个很大的困境。反正我本人在听 Cache 的时候,老师就很喜欢多说一句内存管理也是这么回事。当然老师融会贯通了,他可以说“大象有大象腿啊”,而我作为学生听到的却是“这大象腿就是大象啊”。
在后面的几章中,我会逐个提出内存管理需要解决的问题,然后阐述它的解决办法。最后这些办法堆叠起来,才是我们全部的内存管理系统。
1.3 抽象
在这里记录一下我上操作系统以来看到的最牛逼的话:
操作系统提取“处理器”的概念建立了“进程”的抽象,提取“物理存储器(主存)”的概念建立了“进程(虚拟)地址空间”的抽象,我们提取“外存”的概念建立了”文件系统“的抽象。
可以说,这句话好就好在它描述了操作系统在干啥,以及它是怎样实现他的目标的。操作系统希望在软件(普通软件)和硬件之间做一个中间层。至于为什么需要这个中间层,是因为如果让软件直接管理硬件,软件不仅需要考虑自身功能的实现,还需要考虑与硬件的沟通,与其他同时运行的软件的沟通,这无疑是很麻烦的。操作系统的出现,使得软件只需要考虑自己的事情,而不需要考虑其他的事情。相当于操作系统把原来本该由软件实现的沟通啊,协作啊之类的功能都转移到了自己身上。
所谓的抽象,就是操作系统给软件提供的一种幻象(这个说法不本质),这种幻象可以让软件只操心自己的事情,比如说认为自己独占了处理器,认为独占了地址空间。我们研究操作系统,其实就是理清楚它是怎样制造出这种幻象的。
二、内存管理功能
2.1 实现进程的并行
2.1.1 问题描述
进程是有同时执行的需要的,比如说谁都希望自己可以一边码代码一边听歌。为了让这两个进程都同时运行,我肯定得把他们的代码加载到主存中,不可以加载一份,然后运行一会儿,然后再换进来另一份。这是因为这样换来换去的太慢了,没有办法给用户营造一个同时干两件事的假象。也就是说,主存里必须有两份代码。
主存里有两份代码就会出现很多个问题,比如说进程 A 说我要跳转到地址 100 所在的那条指令,进程 B 也说我要跳转到地址 100 所在的那条指令。这个说法在程序看来没毛病,我编程的时候想要跳转到第 25 条指令,这个指令的地址就是 100,那么我就说我要跳转到地址 100 怎么了。但是一旦主存里放了两个进程的指令,那么地址 100 只可能是一个进程的第 25 条指令,而另一个进程的第 25 条指令并不是地址 100。
这个问题的实质是,当程序员在编程的时候,他可不知道自己写的程序被加载到主存的哪里,他是没办法确定自己跳转的时候要跳去哪里的。访问数据也是这个道理,因为内存中有多个进程的数据,谁能在编程的时候知道自己的数据到底被存到内存的哪个位置去了。这就好像一个人只知道自己住十楼,是没有办法找到自己的家的,因为他不知道自己是哪栋楼哪个单元的。
2.1.2 问题解决
当然最朴素的办法就是让程序员在编写程序的时候,就让他自己注意自己要被内存加载到哪里。这件事情是不可能的,虽然我们经常在现实中这么干,比如我们记忆家地址,就会记住大概 8 号楼一单元 1202。是一个很正常的事情。运行的时候,不可能把每个进程的位置都给固定了,因为为了不发生冲突(就是两个进程加到到一片区域了),我们必须给每个进程都固定一个位置,那么主存的空间一定不够。我们只能这个进程进到内存,挑块地方给他,另一个进程来了,从剩下空着的地方挑一块给他,那个进程走了,那么就把他这块地方给清除了,好给其他进程腾地方。
既然进程被加载到哪里在编写代码的时候不确定,那么我们就在他确定的时候给他记下来不就得了。当进程被加载的时候,我们记录一下他的首地址,比如说是 2000,那么等下次它再访问地址 100 的时候,我们就让他访问 2100 ,这就对了。这个技术被称为“重定位”。
让我们再看一下重定位这个技术,我们发现程序编程的时候用的地址不再是真实的物理地址了,因为要是真实的物理地址,那么说访问 100,那就必须访问物理地址第 100 个存储单元。但是它实际访问的是物理地址 2100 。这个其实就是朴素的虚拟地址。也就是程序编程的时候用到的地址空间并不是真正的物理地址空间,而是一个假的,一个幻象,是需要通过操作系统进行转换才能变成物理地址的一个空间。这个虚假的空间是很好的,程序员编程的时候不再需要考虑加载的问题(本质是考虑与其他进程并行的问题)。
当然这个重定位技术不是没有缺点,每次对虚拟地址的访问都需要经过转换,从这里我们可以看出采用的是加法,而加法是一个很耗时的运算,这导致采用这种技术的会让整个程序变得很慢,因为每次对访问内存都要经历一个加法。
2.2 主存放不下多个进程
2.2.1 问题描述
因为前面我们解决了实现进程并行的问题,那么就会导致另一个问题,就是用户可以同时打开多个进程,那理论上就会出现运行的进程太多了,主存存不下了的情况。那当然不能让用户知道这件事情,多点了几个程序电脑就崩了,那我怎么敢多点程序呢。我们希望给用户营造一种无论打开多少个进程,这些进程都会并行的假象,顶多就是慢一点而已的假象。这就需要我们进一步完善我们的内存管理系统。
2.2.2 问题解决
可以这样解决这个问题,就是如果把程序载入内存的时候,一看剩下的空间,发现好像这个进程放不下,那么就把当前内存中的一个没在工作的进程(理论上只有一个进程在工作)调往外存,给这个新来的进程腾出空间。等到了一定的时机,在把那个外存中的进程调回来(因为这个进程还没结束)。这个方案被叫做“交换”。
有一点需要强调的,存储被换出进程的外存区域被叫做 swap,他不是文件系统的一部分,而是更像内存管理系统的一部分。我们在装 linux 的时候,常说要把 swap 分区搞大一点,就是因为这个大了,方便进程间的并行。
我们审视交换这个技术。我们可以这样理解:就是把磁盘的一部分作为一个大的存储器,而主存作为他的高速缓存。就好像 cache 没必要太大,因为很多数据存在主存一样,按照这样处理的主存也不需要太大,因为很多数据是存在外存中一样。
交换这个技术也是有缺点的,它调入调出内存的单位是一个进程,一个进程这么大,调入调出是很慢的。而且调出的后遗症也很大,当一个进程被调出后,它腾出的主存空间要是有点小,而等待调入的进程比他大,那么这次调出就没用啊。这两个问题的本质都是以进程为单位的颗粒度太大了,是一种粗糙的方法。
2.3 主存放不下一个进程
2.3.1 问题描述
难道只有多个进程的时候,主存才捉襟见肘吗?不是的,有可能一个进程的大小就让主存吃不消了,比如 Photoshop,运行起来几个 GB 不在话下。交换策略是没办法解决的,因为交换的调度单位是进程,一个进程再怎么调度,也是没有办法变小的。
2.3.2 问题解决
这个问题要求更细颗粒度的调度策略,其实虚拟内存几乎呼之欲出,但是为了历史的严谨性,我们得先介绍另一个技术,即“覆盖”。这个技术说的是我们在编程的时候就给程序分好片段,每个片段我们叫做一个“覆盖块(overlap)”,然后我们在运行的时候,是按照覆盖块进行调度的,覆盖块存放在外存上,在需要的时候由操作系统动态地换入换出。
覆盖能解决问题,依靠的是覆盖块是比进程跟小的调度单位,我们可以只在主存中保留一部分进程,而将另一部分暂时用不上的调往外存,这种细颗粒度的划分是关键。
但是我们也应该看出他的缺点,就是程序员很痛苦,他们在编程的时候必须把程序分割成小片段,而且似乎这些小片段的数据依赖关系还得比较弱。这个缺点本质是又让程序员开始思考与硬件的协作,而不能专注于程序自身的功能。
2.4 跟踪主存使用情况
2.4.1 问题描述
每次运行一个进程,都需要在主存中寻找一个合适的空间分配个这个待运行的进程。当一个进程结束运行的时候,都需要释放这个进程占据的空间。这就要求内存管理系统必须具有跟踪内存使用情况的功能。
2.4.2 问题解决
我们有两种数据结构进行内存跟踪,一种是位图,一种是链表。两种方法都是十分的好理解,所以就不赘述了。除了跟踪内存使用情况,还需要有内存分配策略。根据数据结构的不同,策略的具体实现也不同。有首次适配策略,下次适配策略,最佳适配策略,最差适配策略,快速适配策略。不在此赘述。
三、虚拟内存
3.1 虚拟内存机制
虚拟内存就是我在总论里提到的一个完整的内存管理的实现方案,它可以很有效的解决我们上面提出的问题。我们首先看一下虚拟内存的机制:
每个程序拥有自己的地址空间,这个空间被分割成多个小块,每一块被称为一个页面,每一页有连续的地址范围,这些页被映射到物理内存,但并不是所有的页都必须在内存中才能运行程序。当程序引用到一部分在物理内存中的虚拟地址空间的时候,由硬件立刻执行必要的映射。当程序引用到一部分不在物理内存中的地址空间的时,由操作系统负责将确实的部分装入物理内存并重新执行失败的指令。
我们来看一下虚拟内存有没有解决我们提出的三个问题。对于“进程的并行”,虚拟内存也是提供了虚拟地址的,程序员编程的时候是在虚拟地址空间中进行处理的,而转换虚拟地址为物理地址交由操作系统处理。对于主存的大小问题,可以看出页的颗粒度是足够小的,当采用交换的思想后,不仅可以解决“主存放不下多个进程”的问题,也可以解决“主存放不下一个进程”的问题。至于“跟踪内存使用情况”的问题,采用的还是原来的机制。
除此之外,在虚拟内存的实现中,还做了具体的优化,我们在具体实现的时候讲解。
3.2 基本实现
虚拟内存干的是这样的一个事情,它给进程提供一个虚拟地址空间,32 位的操作系统就是 4 GB 大小。然后它把这个虚拟地址空间按照虚拟页大小划分,一般一个虚拟页(Page)是 4 KB。所以可以划分成 $2^{20}$ 这么多页(大约是十的六次方,一百万页)。它对于主存也做相同处理,按照页面大小把主存分割好,每个分出来的主存页面,被叫做“页框(Page Frame)”。我觉得这个名字超级形象,因为把虚拟内存中的页转换到物理内存,就像把一页照片粘到相框里的过程。
虚拟内存中进行虚实转换的数据结构叫做页表。虚拟空间分成多少页,那么这个页表就有多少页表项。在这个页表项上面记录着这个虚拟页在不在主存中,如果在的话,还记录着此时的物理页号。当我们拿到一个虚拟地址,首先把前几位挑出来,那是他的虚拟页号,然后用这个页号去检索页表项,检索出页表项以后看看在不在,如果在的话,就把页表项中记录的物理页号和虚拟地址的页偏移量拼接在一起,就可以获得真实的物理内存地址,然后就可以访问了。
可以看出,比起重定位技术的加法,页表进行虚实转换的时候,与 cache 的思路很像,像是一个全相连的 cache,这种策略避免了加法运算,而改成了位拼接运算,大大提高了虚实转换的效率。此外,因为固定了页面大小,调度的过程不需要程序员的参与,所以简化了编程的复杂度,这也是一种优化。
但是在虚拟内存的实现中,也存在着诸多问题待解决:
- 虚实转换速度不够快
- 如果虚拟地址空间很大,那么页表也会很大
还有诸多权衡
- 置换页面的策略
- 管理后备存储的策略(后备存储就是 swap 技术里的外存空间)
3.3 优化
5.3.1 TLB
首先我们需要弄懂 tlb 的结构,计组认为的 TLB,是长这样的:
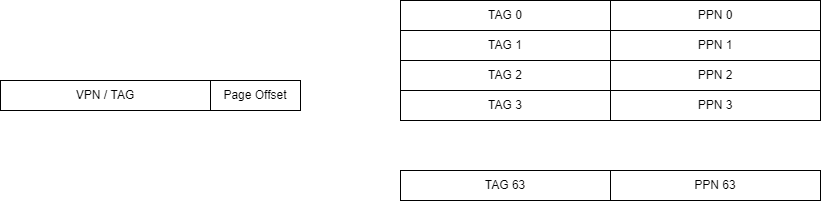
也就是说,TLB 是一个全相连的 cache,既然是全相连,就不由 index 段了。我们用虚拟地址的前 22 位作为 TAG,并行的比较 64 个TLB 的 line,如果 TAG 相等,就说明找到了,反之,这说明没有找到。
不过这个模型还是有些粗糙的,很多细节并没有说明白。
在操作系统指导书里提到,tlb 构建了一个映射关系,我简化一下,就是 $VPN\space \rightarrow\space PPN$ 。当然这是对的了,但是这种说法我就弄成了每个 VPN 都会对应一个 PPN,但是其实这种映射关系只有 64 对。而且叫映射似乎就是一下就射过去了,而不是一个并行的比较过程。
其次就是,我们没有了解具体硬件发生了啥,比如 VPN 是怎样被检索的,被检索到的 PPN 放到了哪里,tlb 缺失以后具体怎么填补。都是没有的。这其实跟协处理器有很大关系。
在了解协处理器之前,我们先来看一下 tlb 的表项,他比计组版本要复杂一些,我们以 MOS 中 64MB (也就是共有 $2^{14}$ 页 )的物理内存为例
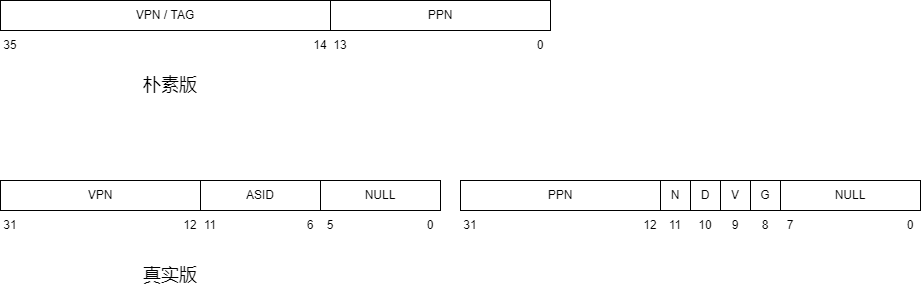
我们来说明一下这些差别:
- 朴素版的 PPN 只有 14 位,是因为物理页框号可以最少用 14 位表示,但是真实版的 PPN 也与 VPN 相同,是 22 位。可能是考虑到不同电脑上内存不同吧,这估计也是 mips_detect_memory() 这个函数的设置。
- 朴素版一个 entry 是 36 位,而真实版一个 entry 是 64 位。这是因为真实版的标志位更多,所以需要的位数就更多
- 朴素版没有 ASID 段,而真实版有。ASID(address space identifier)应该是用于区分不同进程的一个标识符,因为操作系统可以同时运行多个进程,要是不用 ASID 的话,只要进程一切换,那么 TLB 里的所有内容都需要失效(因为进程切换就以为着虚拟地址和物理地址的映射关系切换),而这样是低效的,因为每次 TLB 中的内容清空,就意味着会发生 64 次的冷缺失。
- 朴素版没有物理地址权限标志位(N,D,V,G),而真实版有。这四个标志位的解释见下表
| 标志位 | 解释 |
|---|---|
| N(Non-cachable) | 当该位置高时,后续的物理地址访存将不通过 cache |
| D(Dirty) | 事实上是可写位。当该位置高时,该地址可写;否则任何写操作都将引发 TLB 异常。 |
| V(Valid) | 如果该位为低,则任何访问该地址的操作都将引发 TLB 异常。 |
| G(Global) | 如果该位置高,那么允许不同的虚拟地址映射到相同的物理地址,可能类似于进程级别的共享 |
总结起来就是真实版的 tlb 建立了一个这样的映射 $
然后我们来解决下一个问题,就是 tlb 怎么用的问题。这是一个我之前忽略的点,因为其实我对于 tlb 的定位并不清楚,我本以为它就好像是一个 cache,是对于程序员是透明的,我就在编程的时候写虚拟地址,然后就有硬件(MMU)拿着这个地址去问 tlb,tb再做出相关反应,这一切都是我不需要了解的,但是实际上 tlb 的各种操作,都是需要软件协作的。之所以有这个错误认知,是因为似乎在 X86 架构下确实是由硬件干的,但是由于我们的 MIPS 架构,也就是 RISC 架构,所以似乎交由软件负责效率更高一些。
如果 tlb 是程序员可见的,那么我们必然要管理它,那么我们就需要思考怎样管理它?我们管理它的方式就是设置了专门的寄存器和专门的指令。指令用于读或者写 tlb 中的内容,而寄存器则用于作为 CPU 和 tlb 之间沟通的媒介,就好像我们需要用 hi 和 lo 寄存器与乘除单元沟通一样。这些寄存器,都位于 CP0 中
在协处理器里面与 tlb 有关的寄存器如下表:
| 寄存器 | 编号 | 作用 |
|---|---|---|
| EntryHi | 10 | 保存某个 tlb 表项的高 32 位,任何对 tlb 的读写,都需要通过 EntryHi 和 EntryLo |
| EntryLo | 2 | 保存某个 tlb 表项的低 32 位 |
| Index | 0 | 决定索引号为某个值的 tlb 表项被读或者写 |
| Random | 1 | 提供一个随机的索引号用于 tlb 的读写 |
这里再说一下各个寄存器的域
- EntryHi,EntryLo 的域与 tlb 表项完全相同
- Index 的域:

- Random 的域:

与 tlb 相关的指令
| 指令 | 作用 |
|---|---|
| tlbr | 以 Index 寄存器中的值为索引,读出 TLB 中对应的表项到 EntryHi 与 EntryLo。 |
| tlbwi | 以 Index 寄存器中的值为索引,将此时 EntryHi 与 EntryLo 的值写到索引指定的 TLB 表项中。 |
| tlbwr | 将 EntryHi 与 EntryLo 的数据随机写到一个 TLB 表项中(此处使用 Random 寄存器来“随机”指定表项,Random 寄存器本质上是一个不停运行的循环计数器) |
| tlbp | tlb probe。用于查看 tlb 是否可以转换虚拟地址(即命中与否)根据 EntryHi 中的 Key(包含 VPN 与 ASID),查找 TLB 中与之对应的表项。如果命中,并将表项的索引存入 Index 寄存器。若未找到匹配项,则 Index 最高位被置 1。 |
5.3.2 二级页表
在“MOS阅读”里讲了。
5.3.3 页面置换策略
鸽了
5.3.4 后备存储管理
当我们讨论完了如何将页面从物理内存中换出,但是到底换到外存(磁盘)的哪个部分,却没有讨论,当我们需要将其调入的时候,又是怎么找到这个页面在磁盘上的位置呢?这些问题就是后备存储管理的问题。
最简单的处理就是在磁盘上做一个交换分区(似乎只介绍了这一个方法),这个分区就不在文件系统的管理范围内了。我们用交换分区来存储我们置换出去的页面。
有一种方法叫做静态交换,当启动一个进程的时候,我们就在交换分区中开辟出一片跟进程映像(应该就是虚拟地址空间)相同大小的地区,然后当就进行对应的交换就可以了。
还有一种方法是动态备份,就是当页面换出的时候,我们才为其分配磁盘空间,而且空间并不固定。这样我们就需要记录它的位置了。