加性位置编码
这是 "Attention is All You Need" 中提到的方法,有如下表达:
其中 是 token id 或者说 position id , 是模型维度(也就是 的维度)。
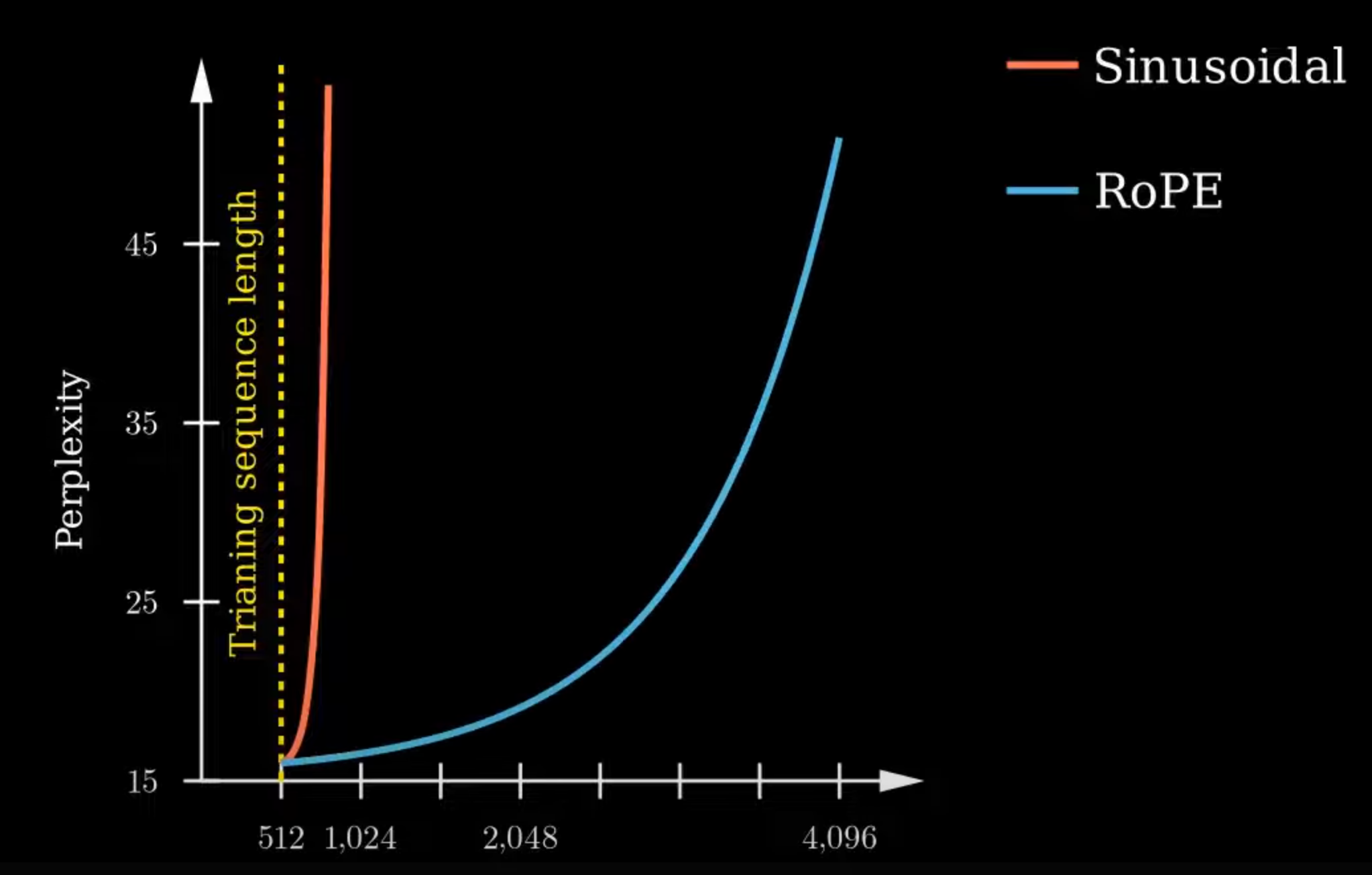
直观上看,就是在原本的 加上 一个随位置变化的角度向量,这样 LLM 就可以获得位置信息了。但是这种加性操作产生的向量变化是非常随机的(一个随机的偏移),这就导致 LLM 很难掌握其中的规律,导致训练成本大(死记硬背),且在更长文本的拓展性弱。如下所示,图中的 即 ,可以看到毫无规律。
这种位置编码一般只需要在输入时编码一次,这个编码会进入每一个 transformer 块中。
RoPE
RoPE 是一种 乘法 位置编码,有如下表述:
其中, 表示第 个 token; 分别表示这个 token 对应的 query 和 key 向量; 是一个近似对角矩阵,每个对角单元是一个 的旋转矩阵。这使得原本的向量中的 个分量,被分成了两两一组,按照不同的速度去旋转。
再讲得细一些,对于第 个 token,它对应一个 key 向量 , 一共有 个分量,这些分量都会旋转过一个角度 (这里的 是上面公式的 ),这个 是 和分量索引 的函数,有:
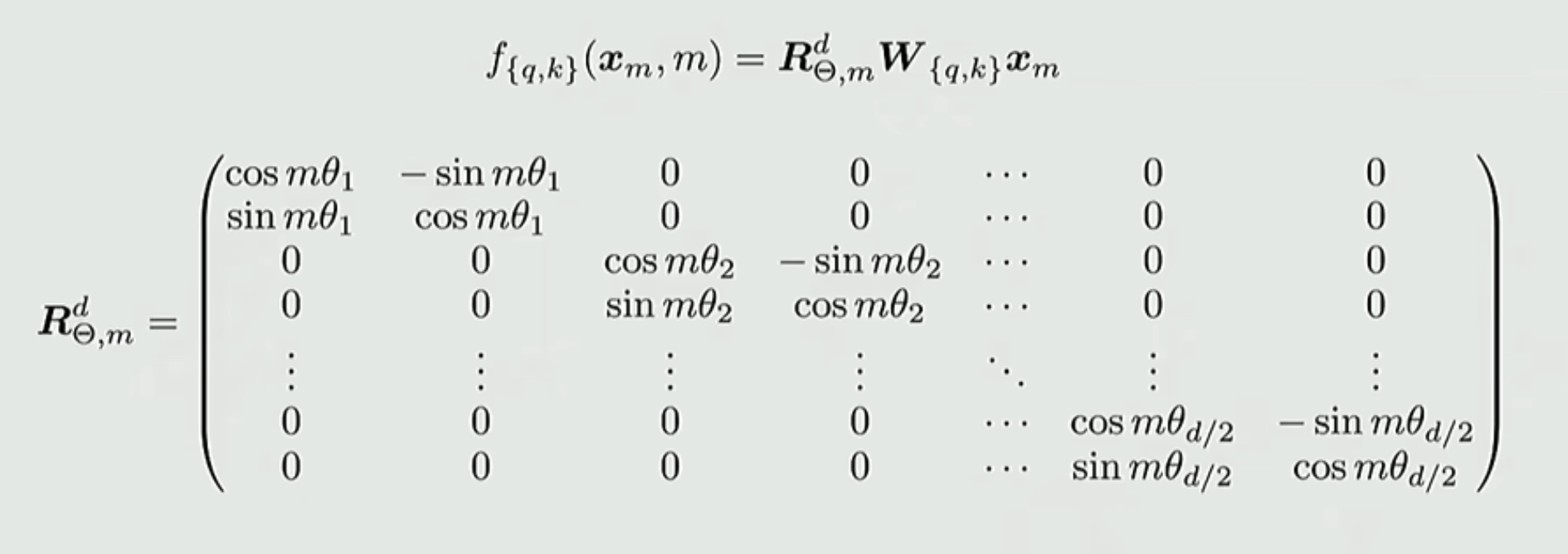
在实际的计算中,我们并不会为每个 都分配一个近似对角旋转矩阵(虽然在数学上是需要的),而只是每个 每两个元素单独处理,并不是矩阵运算,这样避免了形式上的繁复。此外, 这个部分的结果对于不同位置的 token 是相同的,因此是可以 cache 的。
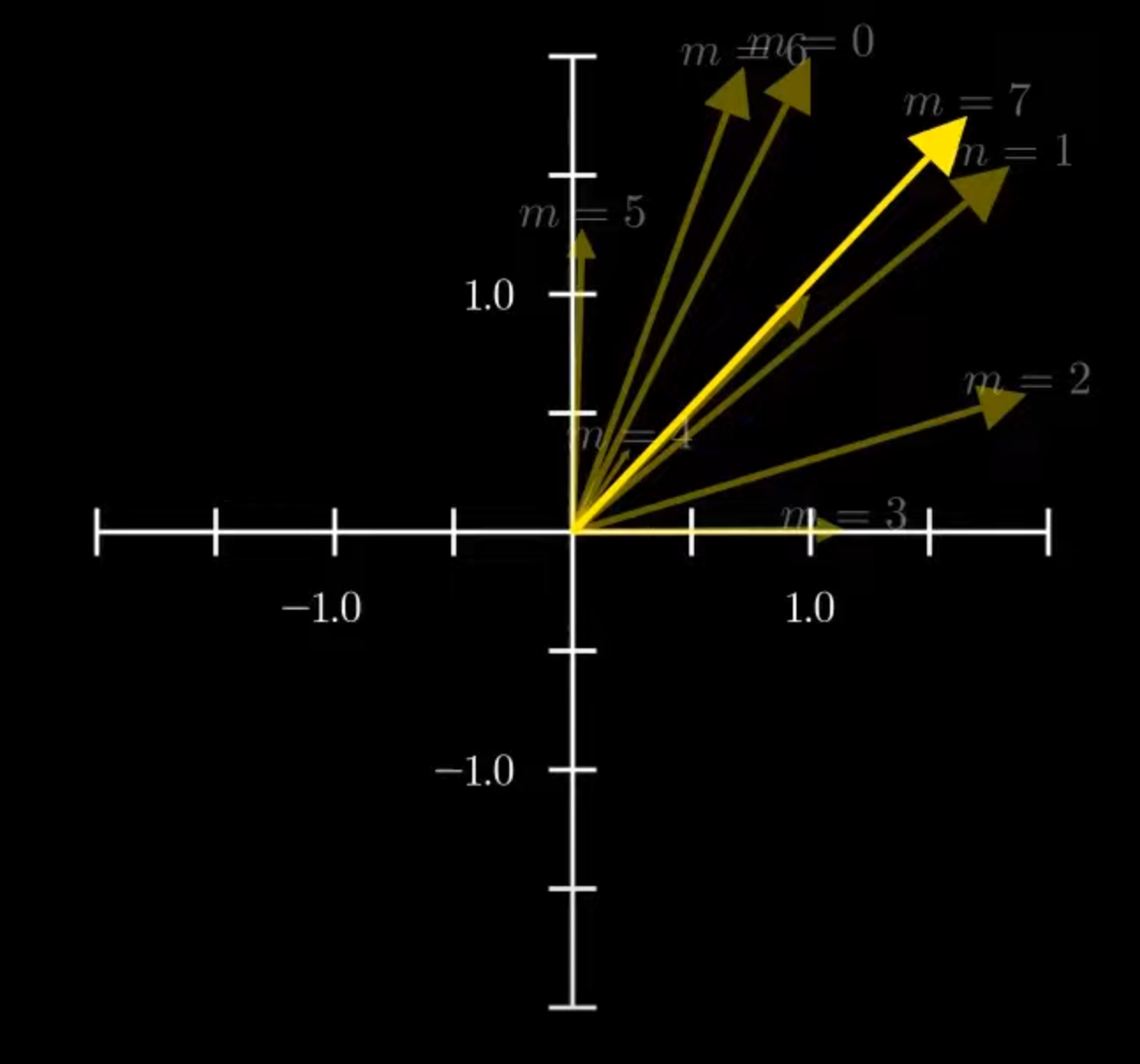
可以看出用这种方法,位置编码变得更有规律,是的 LLM 学习起来更轻松,长文本的拓展性更好。