CP 即 Context Parallelism 。
Ring Self-Attention (RSA)
Sequence Parrallel (SP) 指的是对于很长的输入序列,采用并行的方式,将序列分成多段,然后并行的进行处理。我个人觉得,应该是用在 training 或者 inference prefill 的时候。
更具体而言,SP 并行的对象是 Attention 机制,如下所示:
如果我们将序列分割成多段,那么每个 node 就只会有一部分的 ,为了获得最终的结果,节点通信是在所难免的。问题是,通信的内容是什么?然后我们就会发现,只需要让 矩阵通信,让每个 node 都获得完整的 就可以了。
我们可以仅根据部分 就计算出部分的结果,因为从原理上讲,每个 向量就对应一个输出向量,这个输出向量最终会进入下一层。只有最后一层的最后一个输出向量会变成 decode 阶段生成的第一个 token ,但是这并不意味着其他层的其他向量没有作用。这是我之前的一个误区。
RSA 就是采用 ring 的形式通信 向量,如下所示:

DistAttention
RSA 的缺点在于,对于 Mask Attention ,不同 node 之间存在负载不均衡的问题,因为对于不同行,它们的长度是不一样的。因此我们提出了取长补短的方式:
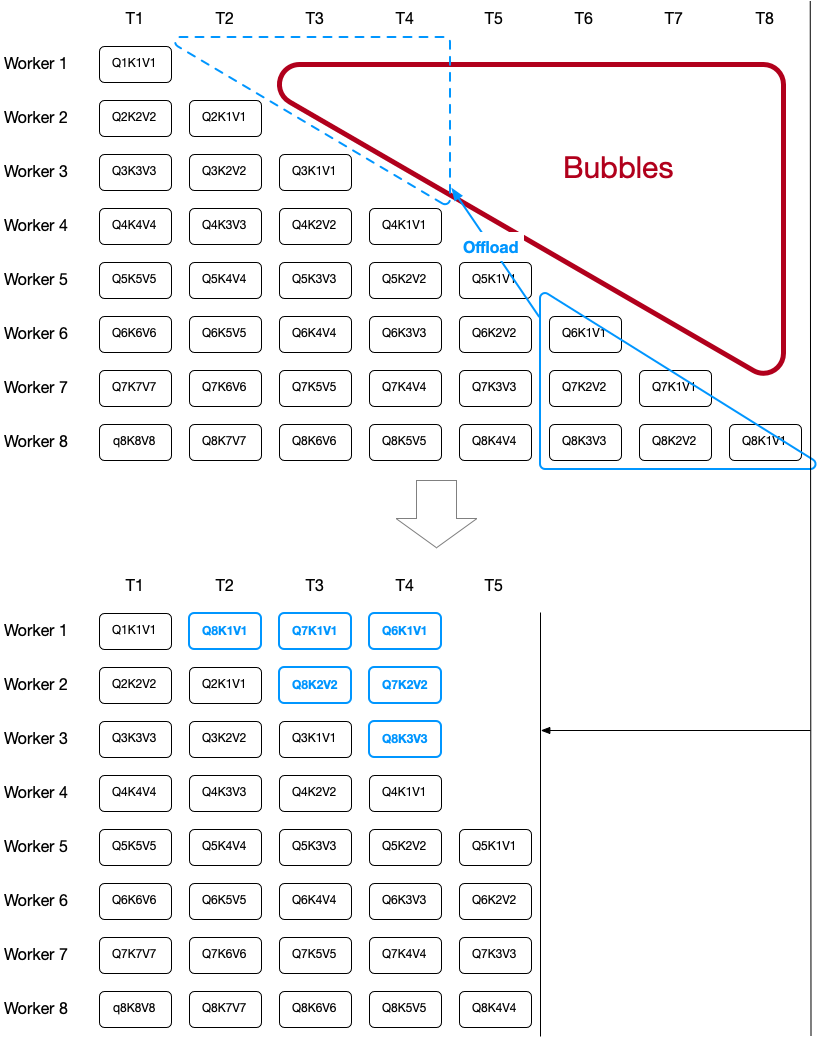
不过似乎这里依然没有用 softmax reduce 的技术,只是在计算完 后,再将其发回原本应该的位置,然后再执行 softmax 。
RingAttention
前面的方法从直观上看,就是每个 node 负责 矩阵的特定行的计算,因为 softmax 是按行执行的,所以在这里,并不会引入处理全局 softmax 的问题。只有当一行被分给不同的 node 的时候,才会存在 softmax reduce 的问题。而这个问题被类似于 FlashAttention 之类的技术解决得很好。
但是这样处理的问题就在于,需要维持一个非常大的 buffer 来容纳整行的 ,而 FlashAttention 技术可以改善这一点,事实上,RingAttention 技术就可以理解为分布式的 FlashAttention 。
Sequence Parallelism
Sequence Parallelism 是 Megatron-LM 中提出的技术,并不是对于 Attention 中 Seq 维度的切分,从图中也可以看出在 Self-Attention 中使用的是 TP 而非 CP。
它真正切分的是 LayerNorm 和 Dropout ,之所以这样切分,是因为这个部分也有 Seq 维度,并且不再适合用 TP 切分(也就是沿着模型权重的某个维度去切分,实际上大的维度是 seq 而非模型权重维度)。
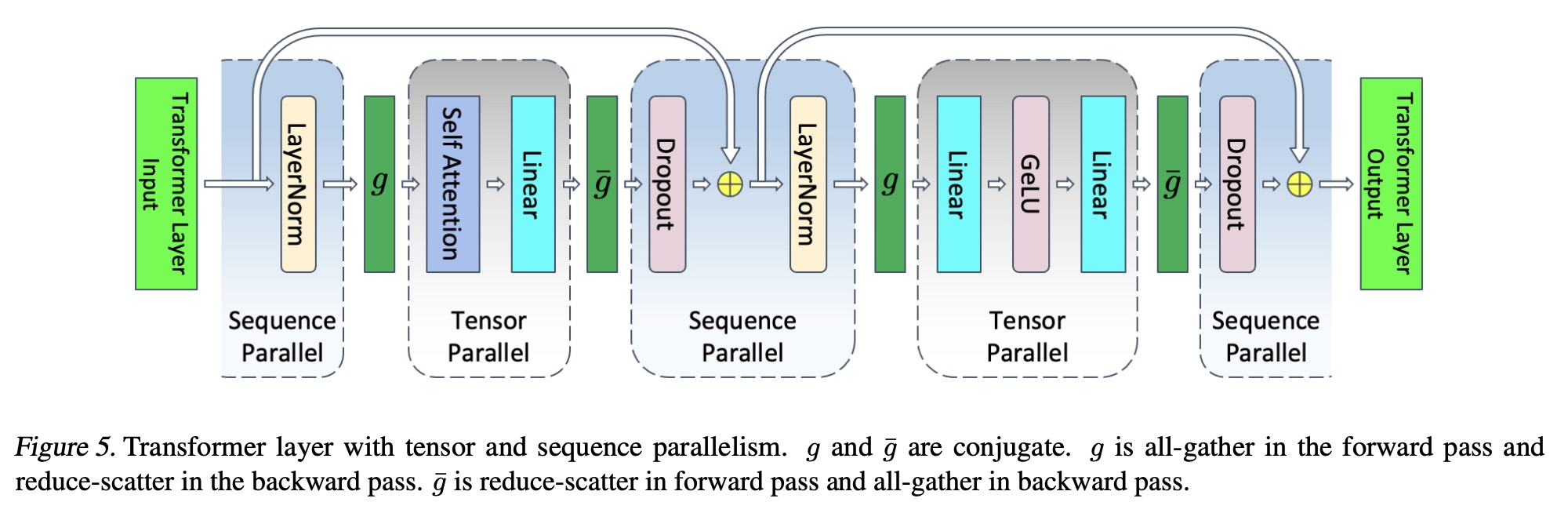
因此 SP 的 size 是与 TP 保持一致的。
DeepSpeed Ulysses
DeepSpeed 引入的技术,我觉得它最大的特点是,在存储方面,确实是以 Seq 维度去分布式的;但是在计算方面,通过首尾两个 all-to-all 的矩阵转置操作,将计算变成了一个以 Head 维度去分布式的思路(虽然图上画的是 d ,但是实际上这里的 d 是 head 与 dim 的乘积,一般而言我们不切分 dim ,只切分 head,因为这会涉及 reduce 操作)。
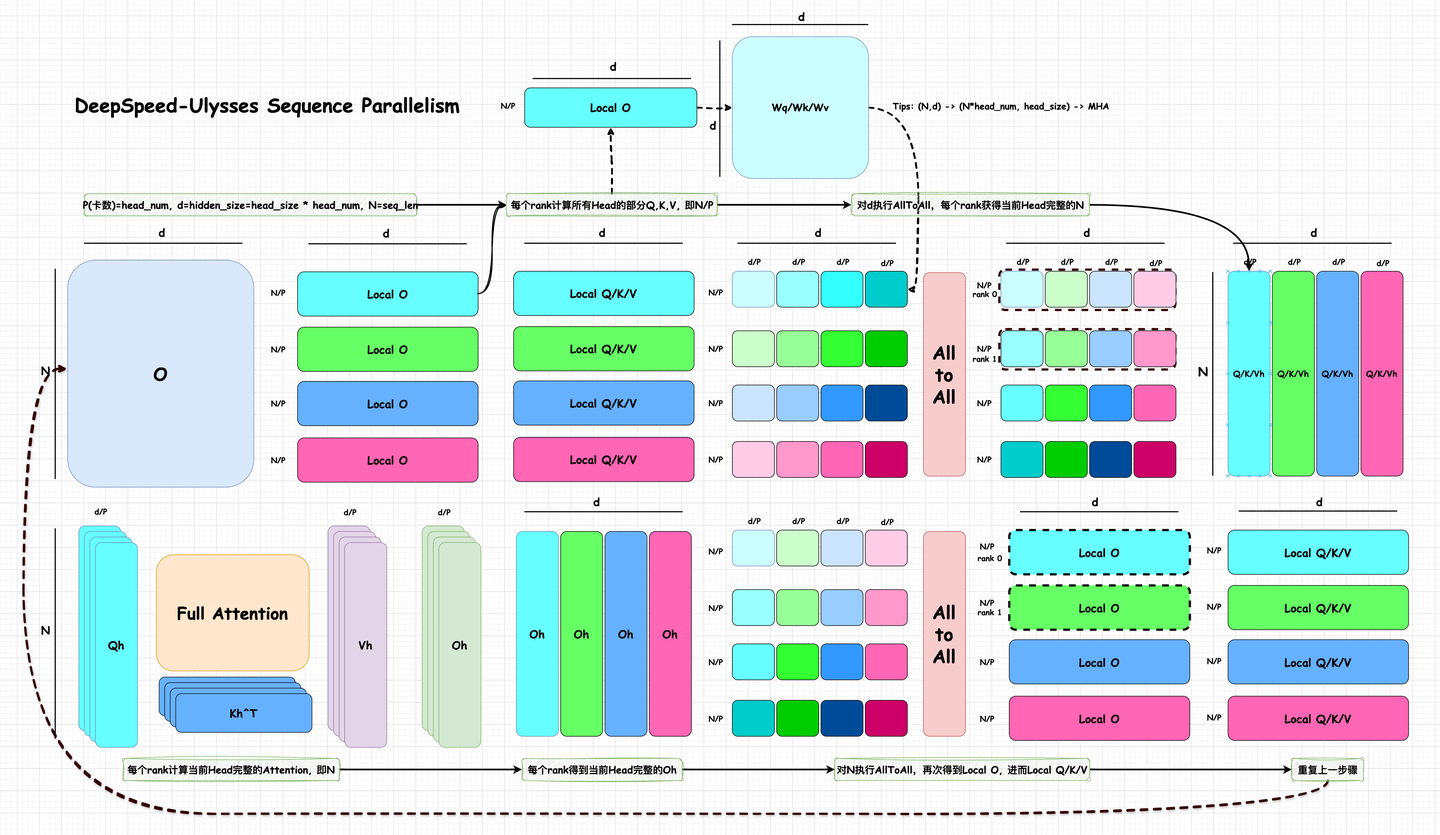
我听说思路这种使用的不多了,因为像 GQA 和 MLA 之类的技术影响,导致 head 数目减少,进而分布式效果并不好。